使用 VS Code AI 工具包转换模型
模型转换是一个集成开发环境,旨在帮助开发人员和AI工程师在本地Windows平台上转换、量化、优化和评估预先构建的机器学习模型。它为从Hugging Face等来源转换的模型提供了一个简化的端到端体验,优化它们并在由NPUs、GPUs和CPUs驱动的本地设备上进行推理。
先决条件
- 安装最新版本的Visual Studio Code.
- 安装 AI 工具包 VS Code 扩展。有关更多信息,请参见 安装 AI 工具包.
创建项目
在模型转换中创建项目是转换、优化、量化和评估机器学习模型的第一步。
-
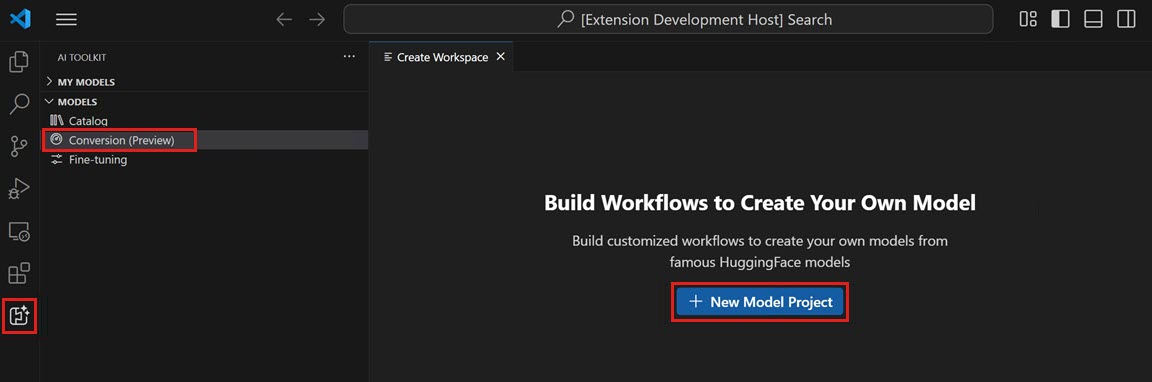
打开AI工具包视图,并选择模型 > 转换以启动模型转换
-
通过选择开始一个新项目新模型项目
-
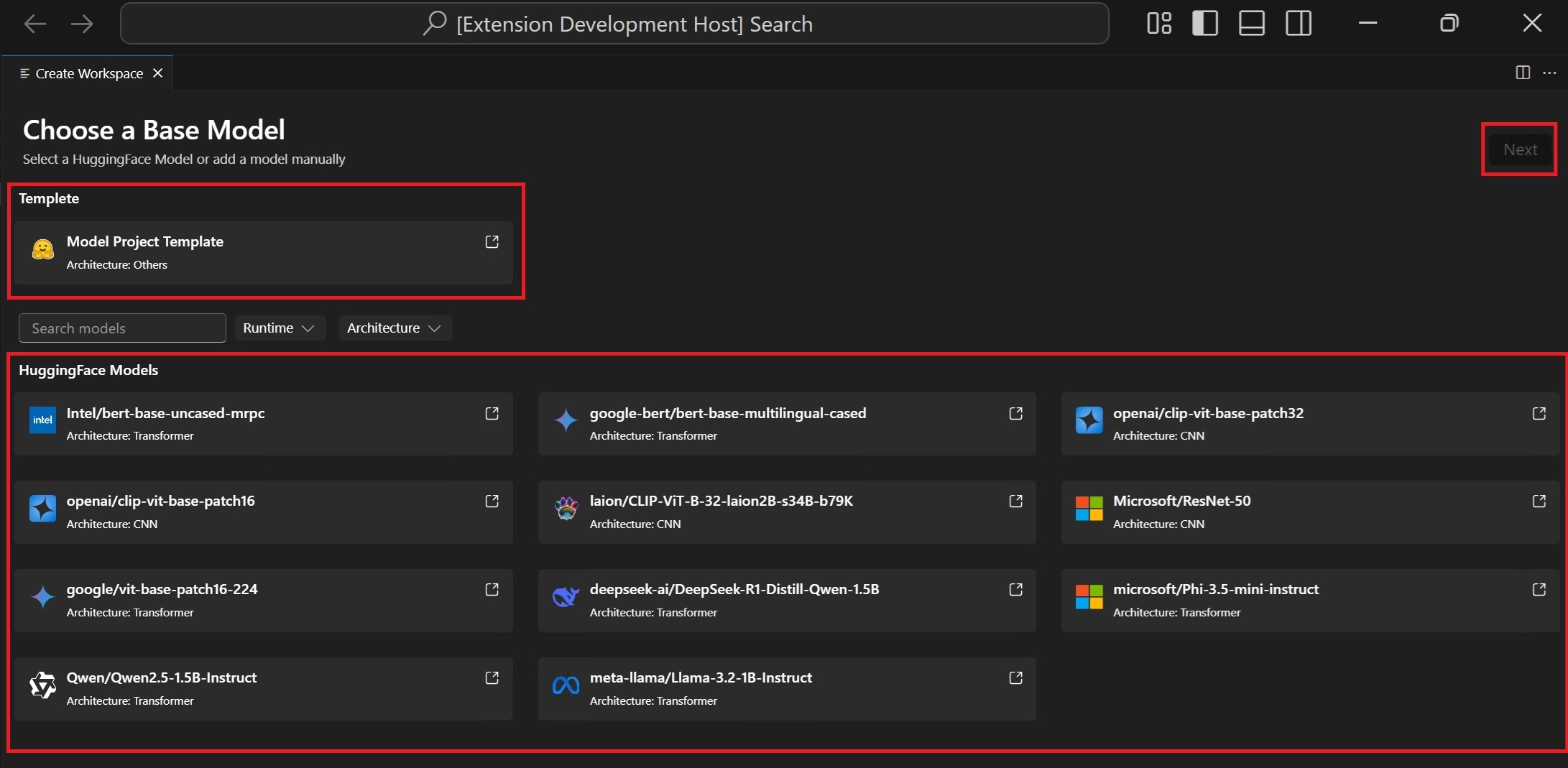
选择一个基础模型
拥抱面模型从支持的模型列表中选择带有预定义配方的基础模型。模型模板如果模型不包含在基础模型中,请选择一个空模板来定制您的指南列表(高级场景)。
-
输入项目详细信息:一个独特的项目文件夹和一个项目名称。
在您选择的项目文件存储位置创建一个带有指定项目名称的新文件夹。
第一次创建模型项目时,可能需要一些时间来设置环境。
如果您还没有完成设置,也没关系。您可以选择在准备好时重新设置环境。

一个自述文件.md文件包含在每个项目中。如果你关闭它,可以通过工作区重新打开。
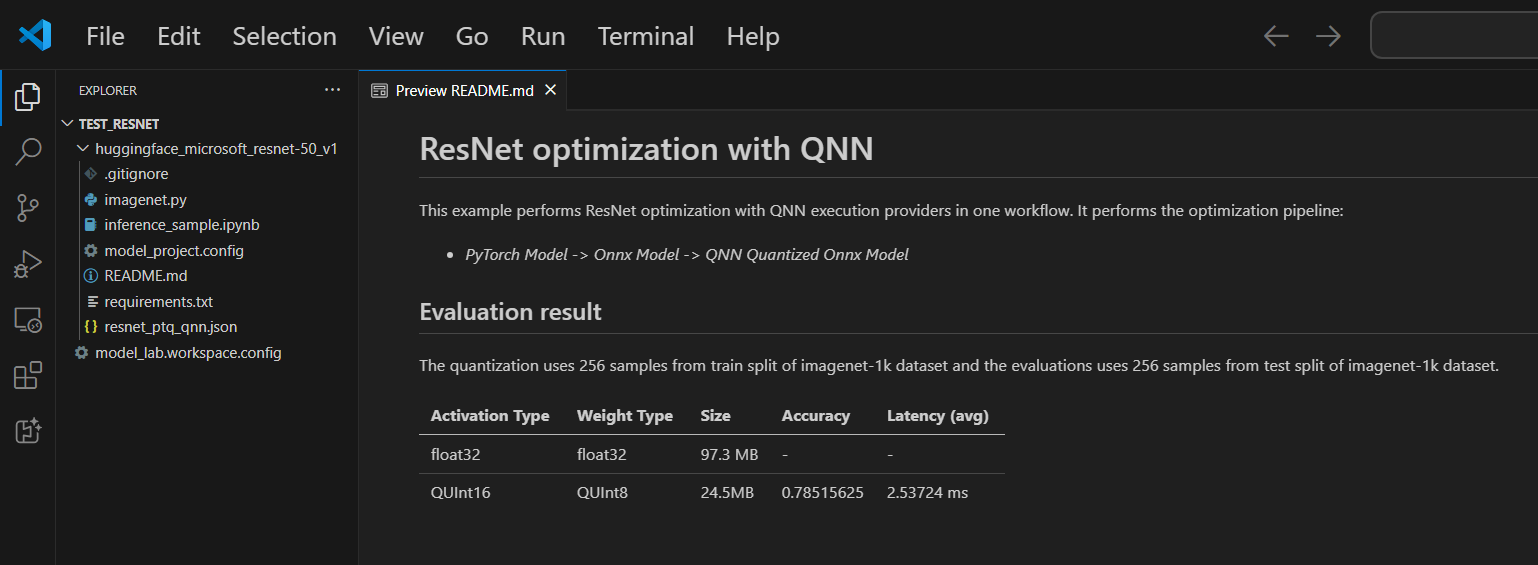
支持的型号
Model Conversion 目前支持越来越多的模型,包括 PyTorch 格式的顶级 Hugging Face 模型。有关详细的模型列表,请参阅:模型列表
(可选)将模型添加到现有项目中
-
打开模型项目
-
选择模型 > 转换,然后在右侧面板选择添加模型。
-
选择一个基础模型或模板,然后选择添加。
在当前项目文件夹中创建一个包含新模型文件的文件夹。
(可选)创建一个新的模型项目
-
打开模型项目
-
选择模型 > 转换,然后在右侧面板上选择新项目。
-
或者,关闭当前的模型项目并创建一个新项目从头开始。
(可选)删除模型项目
-
打开模型项目并选择 模型 > 转换.
-
在右上角视图中,选择省略号 (...) 然后 删除 以删除当前选定的模型项目。
运行工作流
在模型转换中运行工作流是将预构建的机器学习模型转换为优化和量化后的ONNX模型的核心步骤。
-
选择 文件 > 打开文件夹 在 VS Code 中打开模型项目文件夹。
-
查看工作流程配置
- 选择 模型 > 转换
- 选择工作流模板以查看转换配方。

转换
工作流将始终执行转换步骤,该步骤将模型转换为ONNX格式。此步骤无法禁用。
量化
本节使您能够配置量化参数。
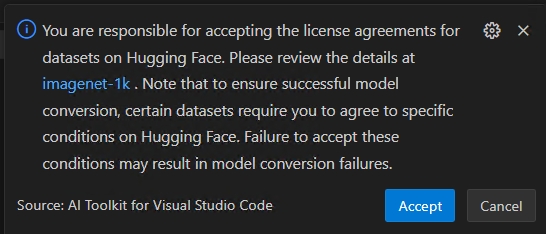
重要Hugging Face 合规警报:在进行量化时,我们需要校准数据集。在继续之前,您可能会被要求接受许可条款。如果您错过了通知,运行过程将暂停,等待您的输入。请确保通知已启用 并且您已接受所需的许可证。
-
激活类型:这是用于表示神经网络中每一层的中间输出(激活)的数据类型。
-
权重类型:这是用于表示模型学习到的参数(权重)的数据类型。
-
量化数据集:用于量化校准的数据集。
如果您的工作流程使用了需要在 Hugging Face 上批准许可协议的数据集(例如 ImageNet-1k),在继续之前,您将被提示接受数据集页面上的条款。这是为了符合法律要求。
-
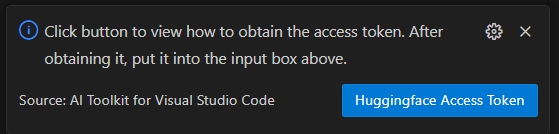
选择 HuggingFace 访问令牌 按钮以获取您的 Hugging Face 访问令牌。
-
选择 打开 以打开Hugging Face网站。
-
在Hugging Face门户网站上获取您的令牌,并粘贴它Quick Pick。按回车。

-
-
量化数据集分割:数据集可以有不同的分割,如验证、训练和测试。
-
量化数据集大小:用于量化模型的数据数量。
有关激活和权重类型的更多信息,请参见数据类型选择。
您也可以禁用此部分。在这种情况下,工作流程将仅将模型转换为ONNX格式,但不会量化模型。
评估
在本节中,您需要选择用于评估的执行提供者(EP),而无需考虑模型转换的平台。
- 评估目标:您希望在目标设备上评估模型。可能的值为:
- 高通NPU:要使用此功能,您需要一个兼容的高通设备。
- AMD神经处理单元:要使用此功能,您需要一个支持的AMD神经处理单元设备。
- Intel CPU/GPU/NPU:要使用此功能,您需要一台配备支持的Intel CPU/GPU/NPU的设备。
- NVIDIA TRT for RTX:要使用此功能,您需要一个支持 TensorRT for RTX 的 Nvidia GPU 设备。
- DirectML:要使用此功能,您需要一个支持 DirectML 的 GPU 设备。
- CPU:任何CPU都可以工作。
- 评估数据集:用于评估的数据集。
- 评估数据集分割:数据集可以有不同的分割,如验证、训练和测试。
- 评估数据集大小:用于评估模型的数据数量。
你也可以禁用这一部分。在这种情况下,工作流程将仅将模型转换为ONNX格式,但不会评估模型。
-
通过选择 运行 来运行工作流
生成一个默认的作业名称,使用工作流名称和时间戳(例如,
bert_qdq_2025-05-06_20-45-00) 以便于跟踪。在作业运行期间,你可以取消作业,方法是选择历史板中操作下的状态指示器或三个点的菜单,并选择停止运行。
Hugging Face 合规警报:在量化过程中,我们需要校准数据集。在继续之前,您可能会被要求接受许可条款。如果您错过了通知,运行过程将暂停,等待您的输入。请确保启用通知并接受所需的许可证。
-
(可选)在云端运行模型转换
云转换使您能够在本地机器没有足够的计算或存储容量时,在云端运行模型转换和量化。要使用云转换,您需要一个 Azure 订阅。
-
选择 在云中运行 在右上角的下拉菜单中。 请注意,评估 部分已禁用,因为云环境中没有用于推理的目标处理器。
-
AI 工具包首先检查是否已准备用于云转换的 Azure 资源。如果需要,系统会提示您输入 Azure 订阅和资源组以提供 Azure 资源。

-
配置完成后,配置信息保存在
model_lab.workspace.provision.config在你的工作区根文件夹中。 此信息用于缓存Azure资源并加速云转换过程。如果你想要使用新的资源,删除此文件并重新运行云转换。 -
Azure 容器应用 (ACA) 作业触发运行云转换。对于正在运行的作业,您可以:
- 选择状态链接以导航到Azure ACA作业执行历史页面。
- 选择 日志 以导航到 Azure 日志分析。
- 选择刷新按钮以获取当前作业状态。

-
如果您没有可用的GPU进行LLM模型转换,您可以使用云运行。 “云运行”选项仅支持模型转换和量化。您需要将转换后的模型下载到本地机器进行评估。
Run with Cloud 不支持使用 DirectML 或 NVIDIA TRT 对 RTX 工作流进行模型转换。
建议列将显示基于您的设备是否准备好运行转换后的模型的推荐工作流程。您仍然可以选择您喜欢的工作流程。模型转换和量化:您可以在任何设备上运行工作流程,除了LLM模型。 量化配置仅针对NPU优化。如果目标系统不是NPU,建议不勾选此步骤。
LLM 模型量化:如果您想量化LLM 模型,需要一个 Nvidia GPU。
如果你想在另一台带有GPU的设备上对模型进行量化,你可以自行设置环境,参考ManualConversionOnGPU。请注意,只有“量化”步骤需要GPU。量化完成后,你可以在NPU或CPU上评估模型。
重新评估的提示
在模型成功转换后,您可以使用重新评估功能再次进行评估,而无需进行模型转换。
前往历史看板并找到模型运行作业。选择模型。重新评估三个点菜单操作
您可以选择不同的EP或数据集进行重新评估

失败工作的建议
如果您的作业被取消或失败,您可以选择作业名称来调整工作流程并重新运行作业。为了避免意外覆盖,每次执行都会创建一个新的历史文件夹,带有其自己的配置和结果。
一些工作流程可能需要您先登录Hugging Face。如果您的工作失败了,输出类似于huggingface_hub.errors.LocalTokenNotFoundError: 需要令牌('token=True'),但未找到令牌。您需要提供令牌或使用 'hf auth login' 或 'huggingface_hub.login' 在 Hugging Face 登录。,导航到https://huggingface.co/settings/tokens并按照说明完成登录过程,然后再次尝试。
如果你的重新评估失败,并且输出警告类似于Microsoft Visual C++ 可再发行组件未安装你需要手动安装以下软件包:
- 微软 Visual C++ 可再发行组件包
- (ARM64 可选)从 Microsoft C++ Build Tools下载。同时查看
使用C++进行桌面开发安装期间的工作负载。
查看结果
历史板在转换中是您跟踪、审核和管理所有工作流程运行的中央仪表板。每次您运行模型转换和评估时,历史板中都会创建一个新的条目——确保完全可追溯和可再现。
-
找到您要审核的工作流运行。每次运行都列出了状态指示器(例如,成功,已取消)。
-
选择运行名称以查看转换配置
-
选择日志在状态指示器下查看日志和详细的执行结果
-
一旦模型成功转换,您可以在Metrics下查看评估结果。每次运行都会显示准确性、延迟和吞吐量等指标。

-
您可以在操作下选择三点菜单,以与转换后的模型进行交互。

复制转换后的模型路径
- 选择 复制模型路径 从下拉菜单中。输出的转换模型路径如下
c://{工作区}/{模型项目}/历史/{工作流}/模型/model.onnx将被复制到你的剪贴板以供参考。对于LLM模型,将复制输出文件夹。
使用示例笔记本进行模型推理
- 选择 在样本中进行推断 从下拉菜单中。
- 选择Python环境
- 您将被提示选择一个Python虚拟环境。
默认运行时是:
C:\Users\{user_name}\.aitk\bin\model_lab_runtime\Python-WCR-win32-x64-3.12.9输入:. - 请注意,缺省运行环境已包含所有所需内容,否则,请手动安装requirements.txt。
- 您将被提示选择一个Python虚拟环境。
默认运行时是:
- 该示例将在 Jupyter Notebook 中启动。您可以自定义输入数据或参数以测试不同的场景。
对于使用云转换的模型,在状态变为成功后,选择云下载图标将输出模型下载到本地机器。
为了避免覆盖任何现有的本地文件,例如配置或历史记录相关的文件,只下载缺失的文件。如果您想下载一个干净的副本,请先删除本地文件夹,然后再次下载。
模型兼容性: 确保转换后的模型支持推理样本中指定的EPs
示例位置: 推理样本存储在历史文件夹中的运行工件旁边。
导出并分享给他人
前往历史板。选择导出以与他人分享模型项目。这会复制不包含历史文件夹的模型项目。如果您想与他人分享模型,请选择相应的作业。这会复制包含模型及其配置的选定历史文件夹。
你所学到的
在本文中,您将学习如何:
- 在 VS Code 的 AI 工具包中创建一个模型转换项目。
- 配置转换工作流程,包括量化和评估设置。
- 运行转换工作流,将预构建模型转换为优化的ONNX模型。
- 查看转换结果,包括指标和日志。
- 使用示例笔记本进行模型推理和测试。
- 导出并分享模型项目给他人。
- 使用不同的执行提供者或数据集重新评估模型。
- 处理失败的作业并调整配置以重新运行。
- 了解支持的模型及其转换和量化的要求。