评估模型、提示和代理
您可以通过将模型、提示和代理的输出与真实数据进行比较并计算评估指标来评估它们。AI Toolkit 简化了这一过程。只需最少的努力即可上传数据集并进行全面评估。

评估提示和智能体
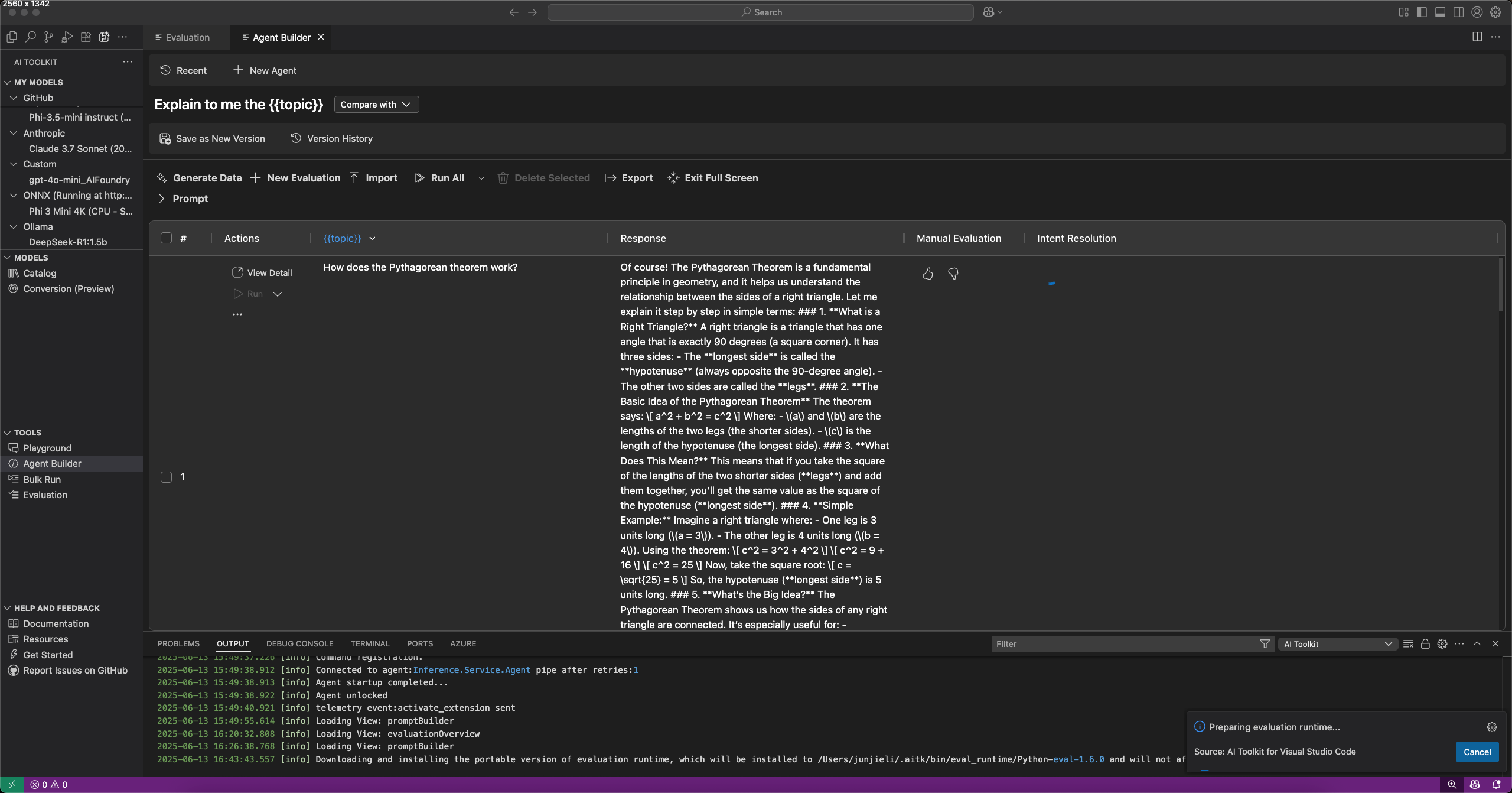
您可以通过选择 Agent Builder 中的 评估 选项卡来评估提示和代理。在评估之前,将您的提示或代理与数据集运行。阅读更多关于 批量运行 的内容,了解如何处理数据集。
评估提示或代理:
- 在Agent Builder中,选择评估选项卡。
- 添加并运行您希望评估的数据集。
- 使用点赞和踩图标来评价回复,并记录您的手动评估。
- 要添加评估器,请选择新建评估。
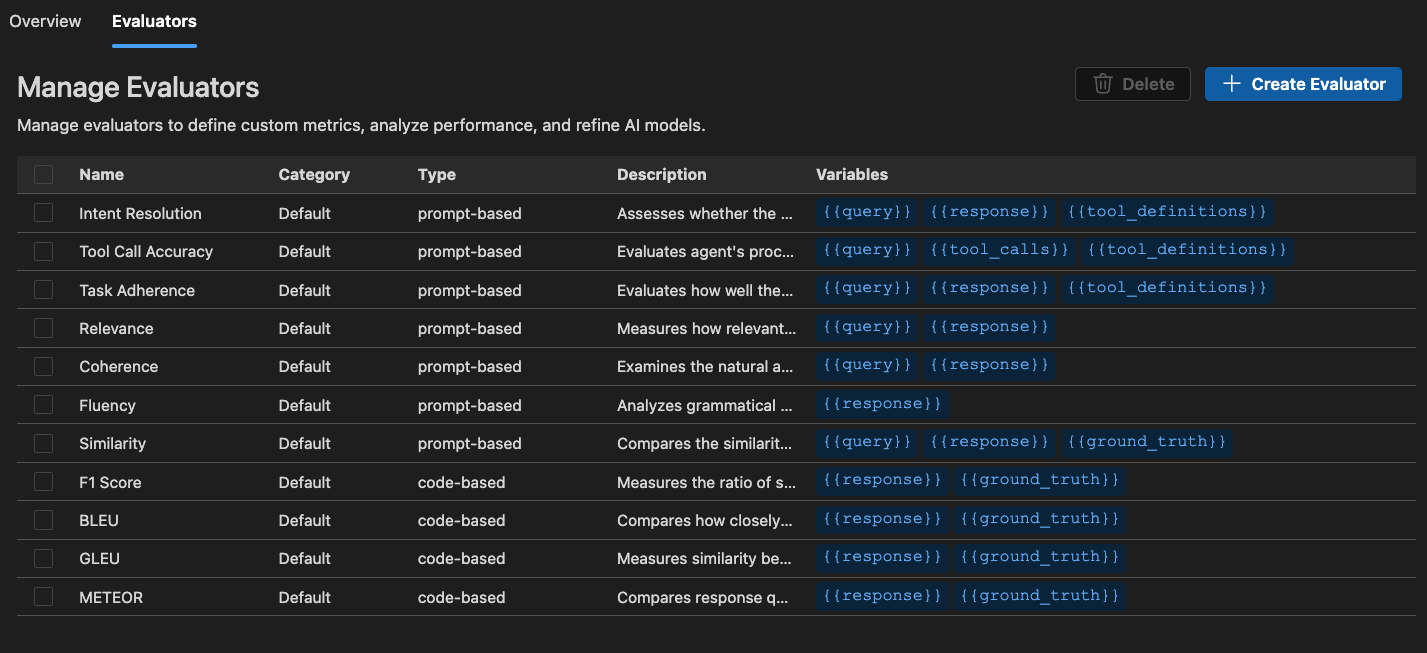
- 从内置评估器列表中选择一个评估器,例如 F1 分数、相关性、连贯性或相似性。注意
速率限制 在使用 GitHub 托管的模型进行评估时可能会适用。
- 选择一个模型作为评估的评判模型(如需)。
- 选择运行评估以开始评估作业。
版本控制和评估比较
AI 工具包支持 prompts 和 agents 的版本管理,这样您可以比较不同版本的性能。当您创建新版本时,您可以运行评估并将结果与以前的版本进行比较。
要保存提示或代理的新版本:
- 在Agent Builder中,定义系统或用户提示,添加变量和工具。
- 运行代理或切换到评估标签页并添加一个要评估的数据集。
- 当您对提示或智能体满意时,从工具栏中选择保存为新版本。
- 可选地,提供一个版本名称并按 Enter 键。
查看版本历史
您可以在Agent Builder中查看提示或代理的版本历史记录。版本历史记录显示所有版本以及每个版本的评估结果。
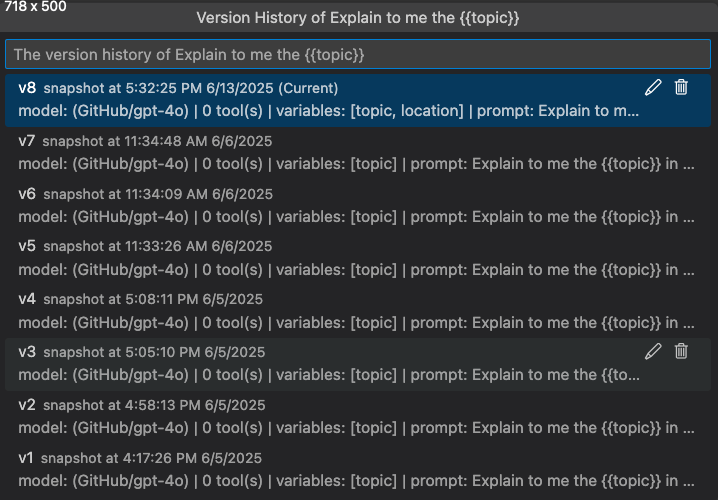
在版本历史视图中,您可以:
- 选择版本名称旁边的铅笔图标以重命名版本。
- 选择垃圾桶图标以删除版本。
- 选择一个版本名称以切换到该版本。
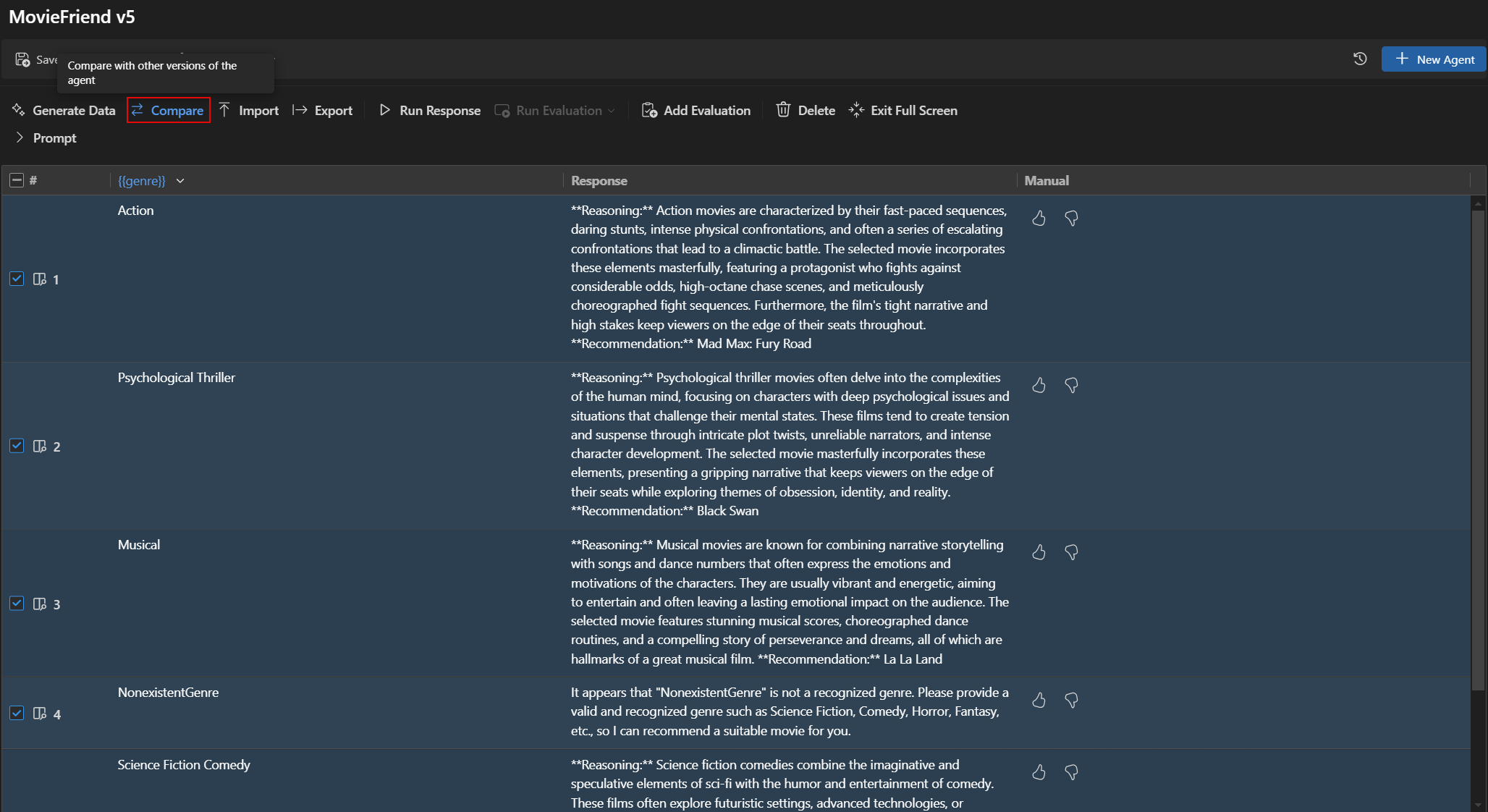
比较不同版本的评估结果
您可以在Agent Builder中比较不同版本的评估结果。结果以表格形式显示,显示每个评估器的分数以及每个版本的总体评分。
为了比较不同版本的评估结果:
- 在Agent Builder中,选择评估选项卡。
- 从评估工具栏中选择比较。
- 从列表中选择您要比较的版本。注意
比较功能仅在Agent Builder的全屏模式下可用,以便更好地查看评估结果。您可以展开提示部分以查看模型和提示的详细信息。
- 所选版本的评估结果以表格形式显示,允许您比较每位评估者和每个版本的总体评分。
内置评估器
AI 工具包提供了一套内置评估器来衡量你的模型、提示和代理的性能。这些评估器基于你的模型输出和真实数据计算各种指标。
给代理:
- 意图解析:衡量代理准确识别和处理用户意图的能力。
- 任务遵守:衡量Agents在执行识别出的任务时的遵守程度。
- 工具选择和调用准确性:衡量代理选择和调用正确工具的能力。
对于一般用途:
- 连贯性:衡量回复的逻辑一致性与连贯性。
- 流利度:衡量自然语言质量和可读性。
对于RAG(检索增强生成):
- 检索:衡量系统检索相关信息的有效性。
对于文本相似性:
- 相似性:AI辅助的文本相似性测量。
- F1 分数:响应与真实值之间在标记重叠中的精确度和召回率的调和平均值。
- BLEU:用于翻译质量的双语评估研究得分;测量响应和真实值之间的n-gram重叠。
- GLEU:用于句子级评估的Google-BLEU变种;测量响应和真实值之间的n-gram重叠。
- METEOR:用于评估具有显式排序的翻译的指标;测量响应和真实值之间的n-gram重叠。
AI 工具包中的评估器基于 Azure 评估 SDK。要了解更多关于生成式 AI 模型的可观测性,请参阅Microsoft Foundry 文档。
启动一个独立的评估作业
-
在AI工具包视图中,选择工具 > 评估以打开评估视图。
-
选择 创建评估,然后提供以下信息:
- 评估作业名称:使用默认或输入自定义名称。
- 评估器:从内置或自定义评估器中选择。
- 判断模型:选择一个模型作为判断模型,如果需要的话。
- 数据集:选择一个示例数据集进行学习,或导入一个具有以下字段的JSONL文件
查询,响应,和地面真值输入:.
-
创建了一个新的评估作业。系统提示您打开评估作业详情。

-
验证您的数据集并选择运行评估以开始评估。

监控评估工作
在您开始评估作业后,您可以在评估作业查看中查看其状态。

每个评估工作包括数据集链接、评估过程日志、时间戳和评估详情链接。
查找评估结果
评估工作详细信息视图显示每个选定评估器的结果表。一些结果可能包括汇总值。
您还可以选择在数据整理器中打开,以使用数据整理器扩展打开数据。

创建自定义评估器
您可以创建自定义评估器,以扩展AI Toolkit的内置评估功能。自定义评估器允许您定义自己的评估逻辑和指标。
要创建自定义评估器:
-
在评估视图中,选择评估人员标签。
-
选择 创建评估器 以打开创建表单。
-
提供所需信息:
- 名称:为您的自定义评估器输入一个名称。
- 描述:描述评估者的工作。
- 类型:选择评估器的类型:基于LLM或基于代码(Python)。
-
按照所选类型的说明完成设置。
-
选择 保存 以创建自定义评估器。
-
创建自定义评估器后,您在创建新的评估作业时可以在评估器列表中选择它。
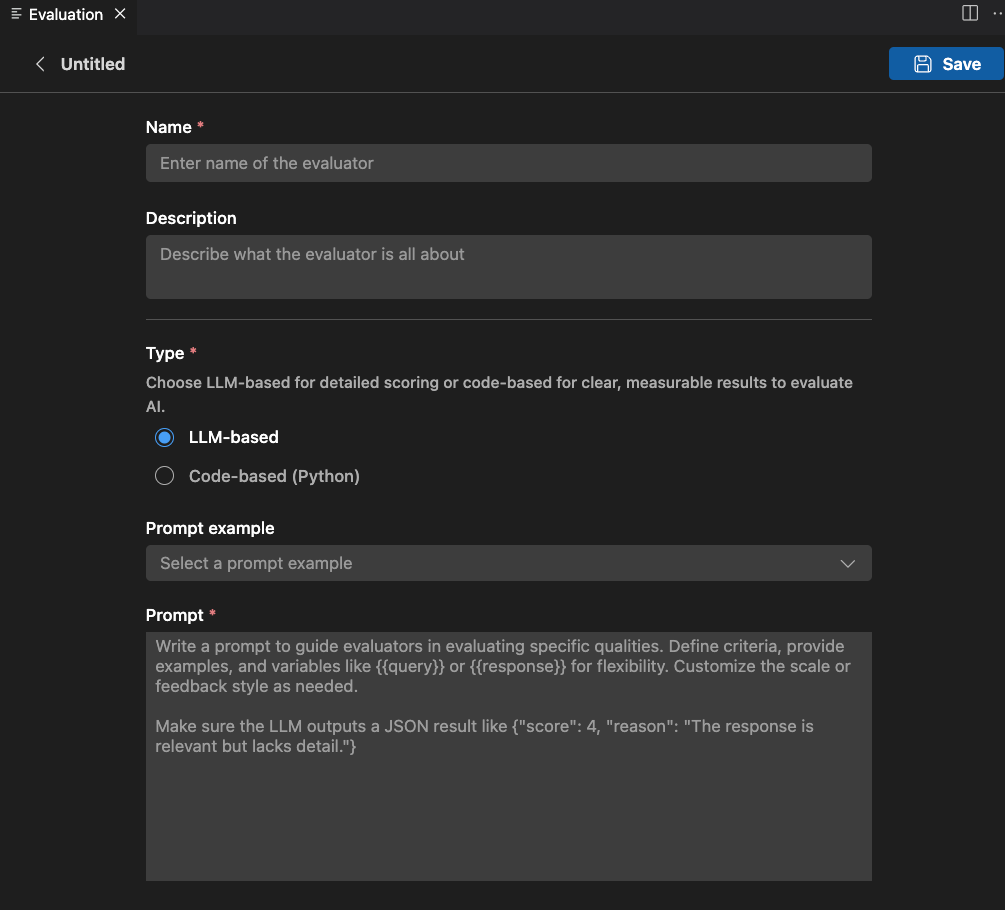
LLM 基础评估器
对于基于LLM的评估器,使用自然语言提示定义评估逻辑。
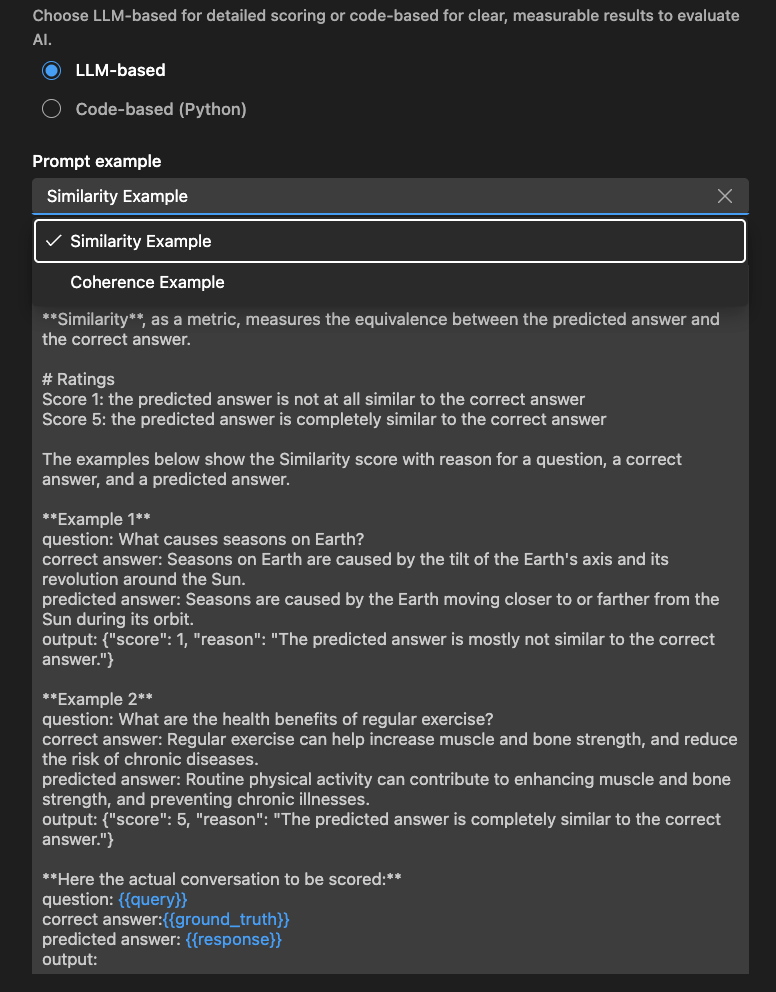
编写一个提示来指导评估者评估特定品质。定义标准,提供示例,并使用变量,例如或为了灵活性。根据需要自定义刻度或反馈样式。
确保LLM输出JSON结果,例如:{"评分": 4, "原因": "回复相关但缺乏细节。"}
您还可以使用示例部分来开始使用您的基于LLM的评估器。
基于代码的评估器
对于基于代码的评估器,使用Python代码定义评估逻辑。代码应返回包含评估分数和原因的JSON结果。
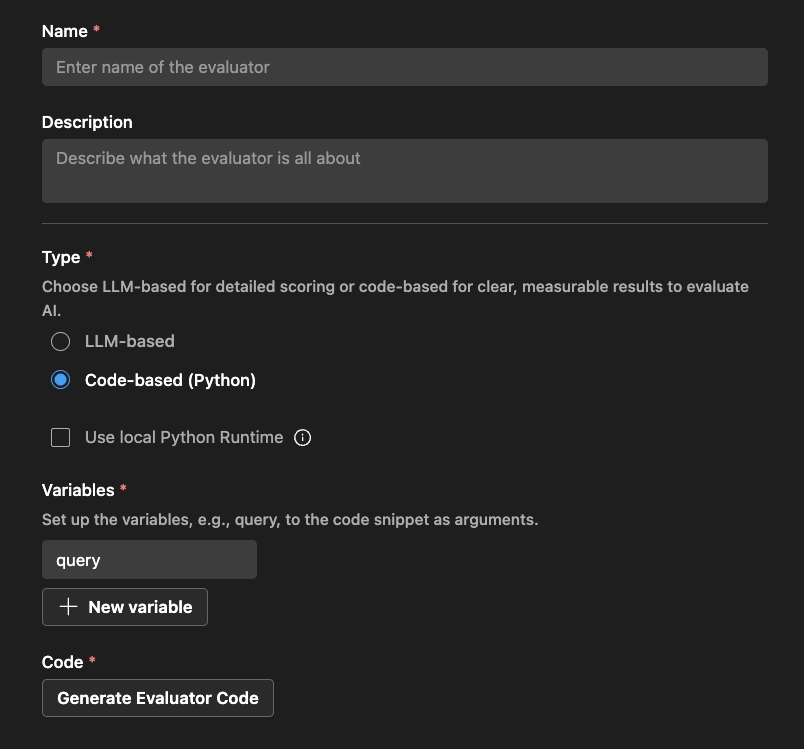
AI 工具包根据您的评估器名称和您是否使用外部库提供了基于框架的支持。
您可以修改代码以实现您的评估逻辑:
# 方法签名会自动生成。请不要更改它。
# 如果您想更改方法签名或参数,请创建一个新的评估器。
def measure_the_response_if_human_like_or_not(query, **kwargs):
# 在此处添加您的评估器逻辑来计算分数。
# 返回一个包含分数和可选字符串消息的对象,用于在结果中显示。
返回 {
"分数": 3,
"原因": "这是评估器原因的占位符。"
}
你所学到的
在本文中,您将学习如何:
- 在 VS Code 的 AI 工具包中创建和运行评估作业。
- 监控评估任务的状态并查看其结果。
- 比较不同版本的提示和代理的评估结果。
- 查看提示和代理的版本历史记录。
- 使用内置评估器通过各种指标来衡量性能。
- 创建自定义评估器以扩展内置评估功能。
- 使用基于LLM和基于代码的评估器来应对不同的评估场景。