微调模型
微调AI模型是一种常见做法,允许您使用自定义数据集在具有GPU的计算环境中运行微调作业,以在预训练模型上进行。AI Toolkit目前支持在本地机器(具有GPU)或在云(Azure Container App)中使用GPU微调SLMs。
微调模型可以下载到本地,并使用GPU进行推理测试,或者量化后在CPU上本地运行。微调模型也可以部署到云环境中作为远程模型。
使用 VS Code AI 工具包在 Azure 上微调 AI 模型(预览版)
VS Code 的 AI 工具包现在支持在 Azure 容器应用中部署模型微调并在云端托管推理端点。
设置您的云环境
-
要在您的远程 Azure Container Apps Environment 中运行模型微调和推理,请确保您的订阅具有足够的 GPU 容量。提交一个支持工单以请求您应用程序所需的容量。获取更多关于 GPU 容量的信息
-
确保你有一个HuggingFace账户并且生成一个访问令牌,如果你在HuggingFace上使用私有数据集或者你的基础模型需要访问控制。
-
如果您微调Mistral或Llama,请在HuggingFace上接受许可证。
-
在 VS Code 的 AI 工具包中启用远程微调和推理功能标志
- 通过选择打开VS Code设置文件 -> 首选项 -> 设置.
- 导航到 扩展 并选择 AI 工具包.
- 选择“在 Azure Container Apps 上启用微调和推理” 选项。
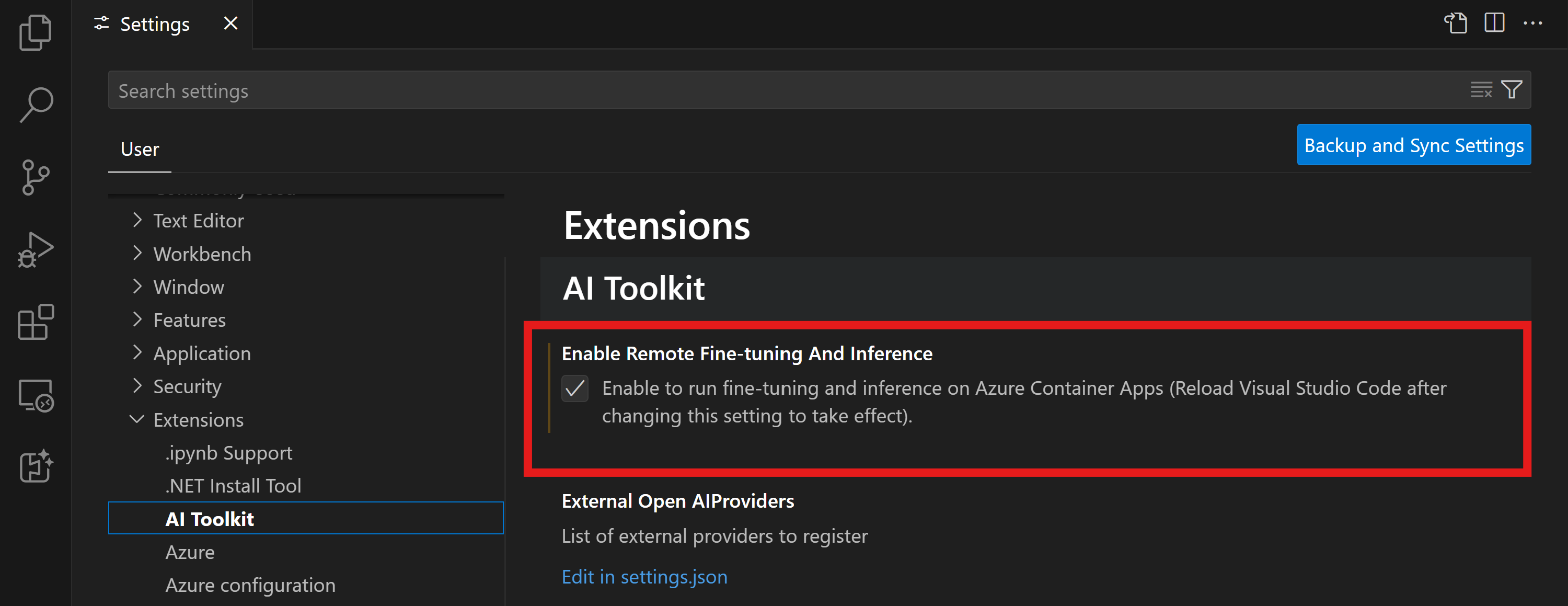
- 重新加载 VS Code 以使更改生效。
构建一个微调项目
- 运行
AI 工具包:专注于工具视图在命令面板中 (⌃⌘P (Windows, Linux ⌃+Shift+P)) - 导航到
微调访问模型目录。选择一个模型进行微调。为您的项目命名并选择其在您机器上的位置。然后,点击“配置项目” 按钮。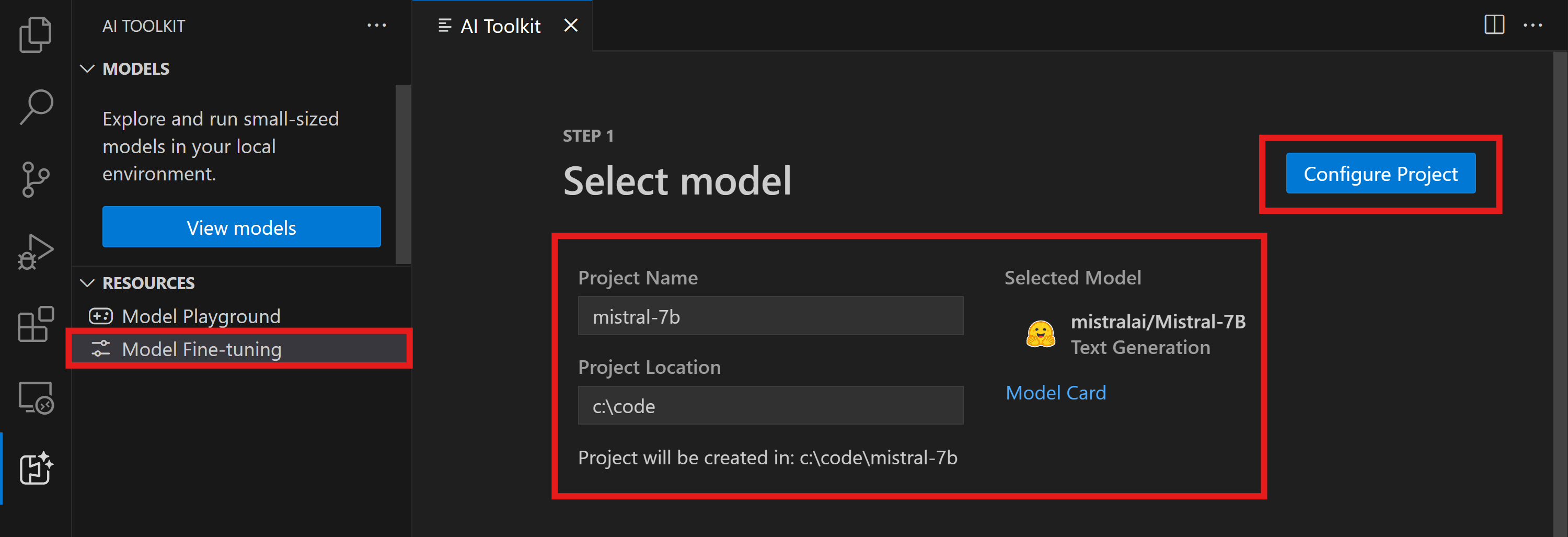
- 项目配置
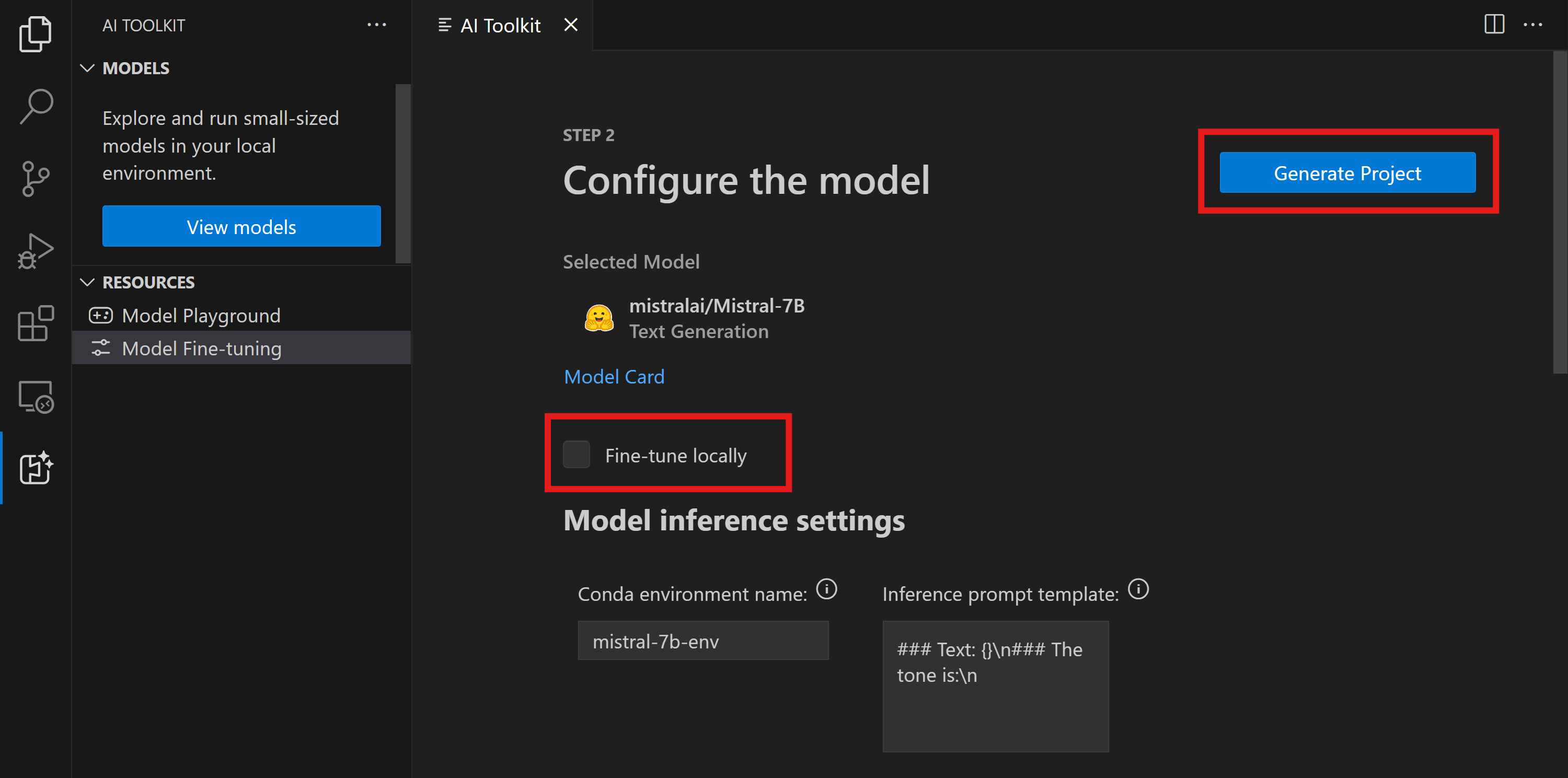
- 避免启用"本地微调"选项。
- The Olive 配置设置将出现预设的默认值。请根据需要调整和填写这些配置。
- 继续进行 生成项目。此阶段利用WSL并涉及设置新的Conda环境,为未来的更新做好准备,包括开发容器。
- 选择“在工作区中重新启动Windows”以打开你的微调项目。
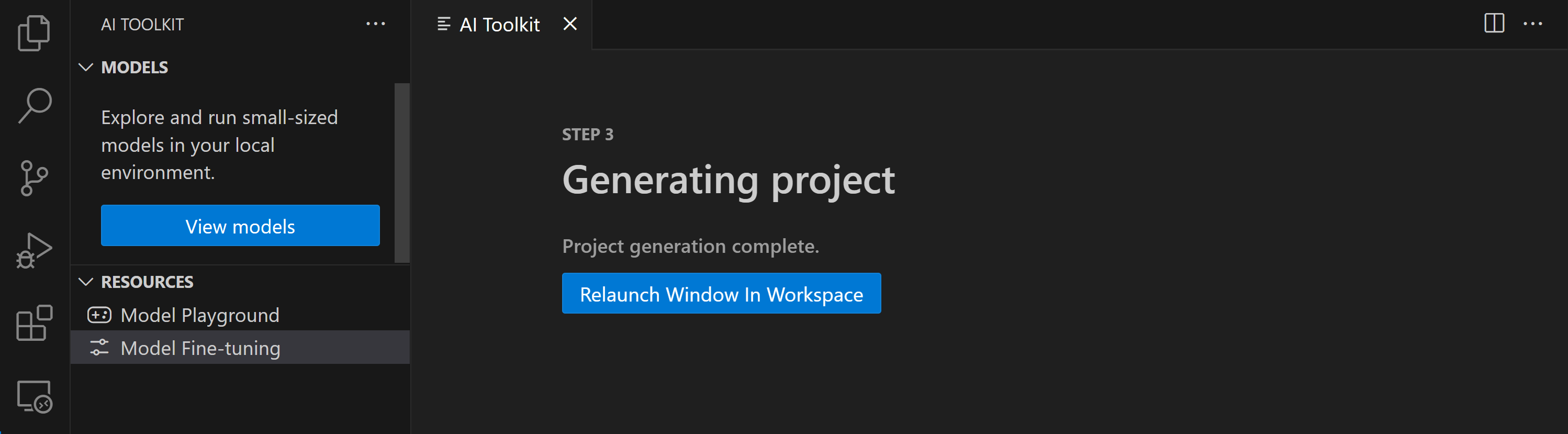
该项目目前在VS Code的AI Toolkit中既可以本地运行也可以远程运行。如果你在创建项目时选择"在本地微调",它将在WSL中 exclusive 地运行,不使用云资源。否则,项目将被限制在远程Azure容器应用环境中运行。
提供 Azure 资源
要开始,您需要为远程微调提供 Azure 资源。从命令面板中查找并执行AI 工具包:为微调提供 Azure 容器应用作业在此过程中,系统将提示您选择您的 Azure 订阅和资源组。
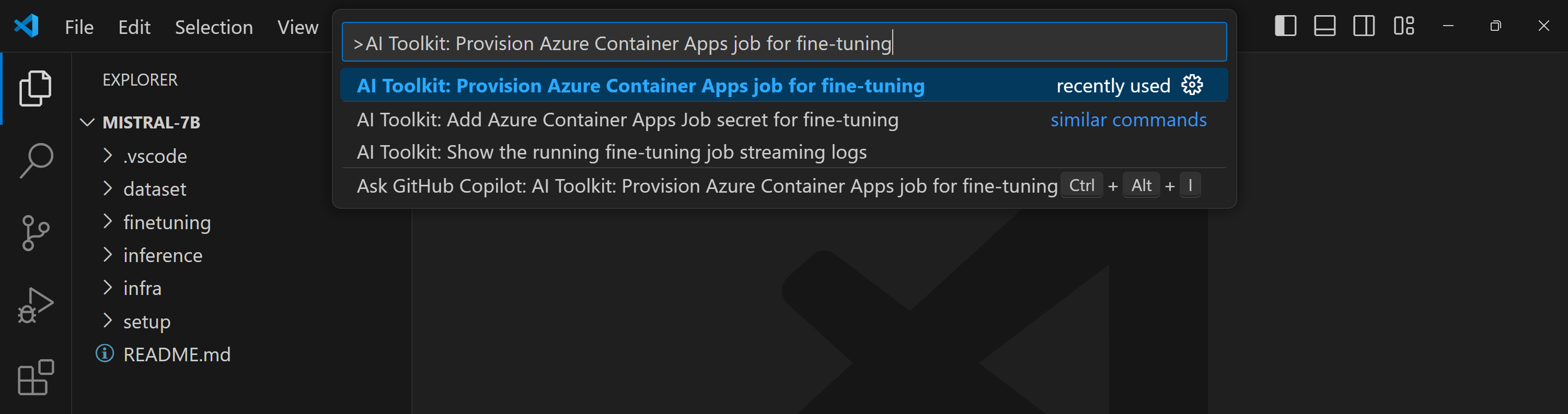
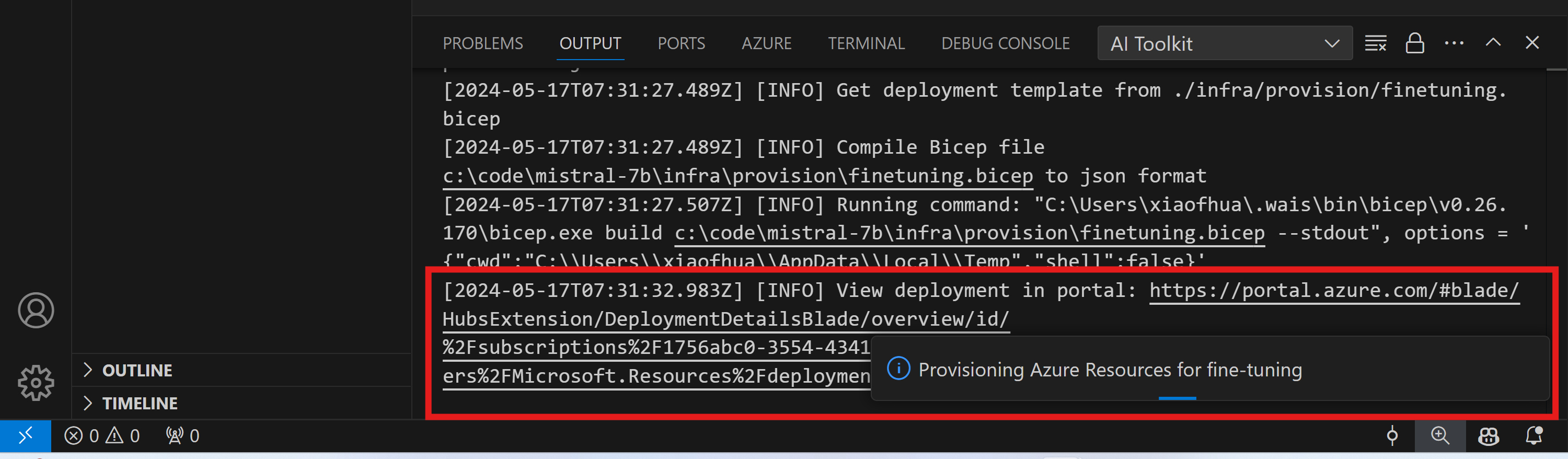
通过输出通道中显示的链接监控供应的进展。
运行微调
要启动远程微调作业,请运行AI 工具包:运行微调在命令面板中输入命令。

然后扩展执行以下操作:
-
将您的工作区与Azure Files同步。
-
使用指定的命令触发Azure容器Appjob
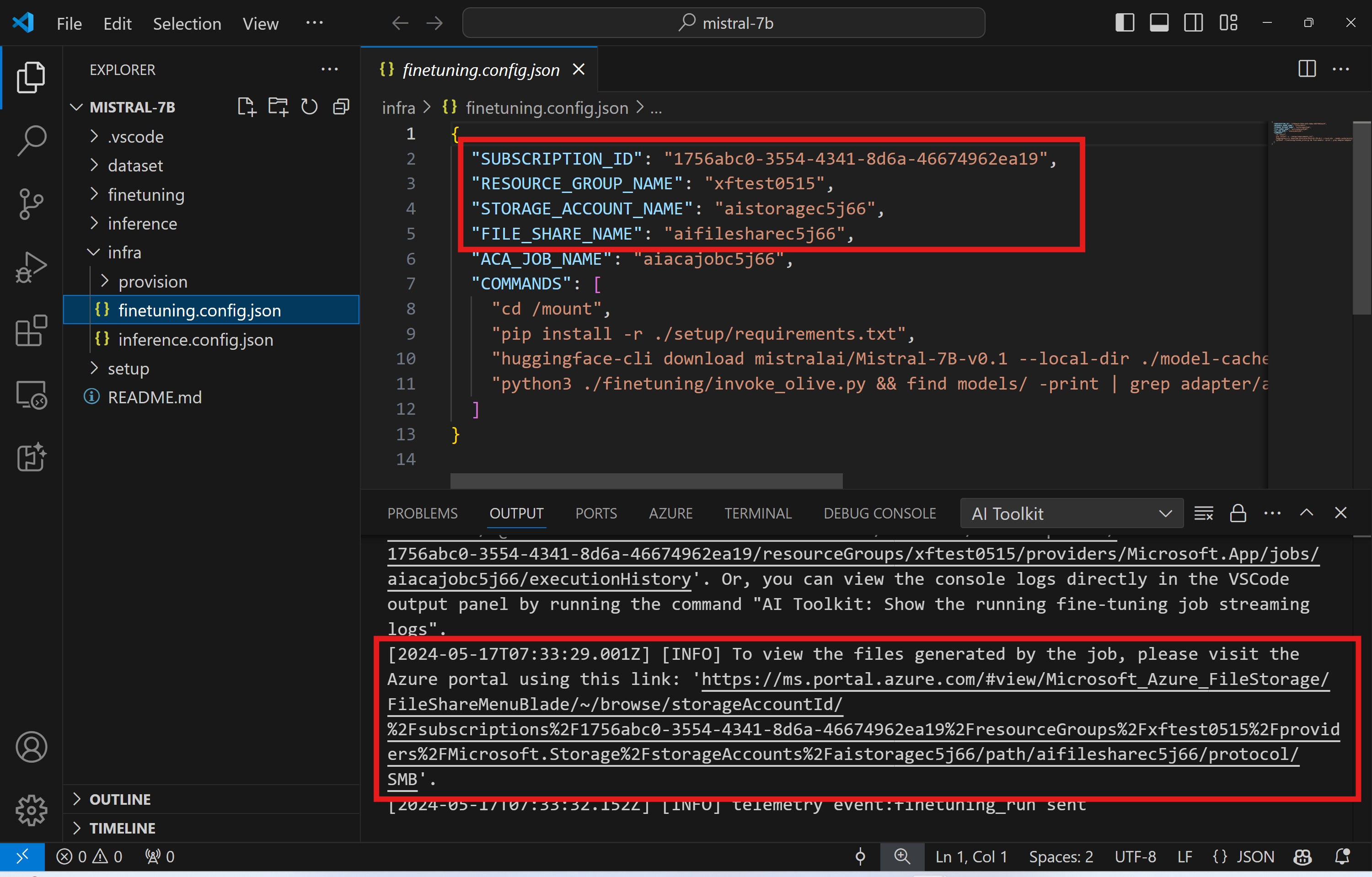
./infra/fintuning.config.json输入:.
QLoRA 将用于微调,并且微调过程将为模型在推理期间创建 LoRA 适配器。
微调的结果将存储在Azure文件中。
要浏览Azure文件共享中的输出文件,您可以使用输出面板中提供的链接导航到Azure门户。或者,您可以直接访问Azure门户并找到名为的存储帐户存储账户名称如在 中定义的./infra/fintuning.config.json和名为 的文件共享文件共享名称如在 中定义的./infra/fintuning.config.json输入:.
查看日志
一旦微调作业开始,您可以通过访问Azure门户来访问系统和控制台日志。
或者,您可以在 VSCode 的输出面板中直接查看控制台日志。
该任务可能需要几分钟才能启动。如果已经有正在运行的任务,当前任务可能会被排队并稍后开始。
查看和查询 Azure 日志
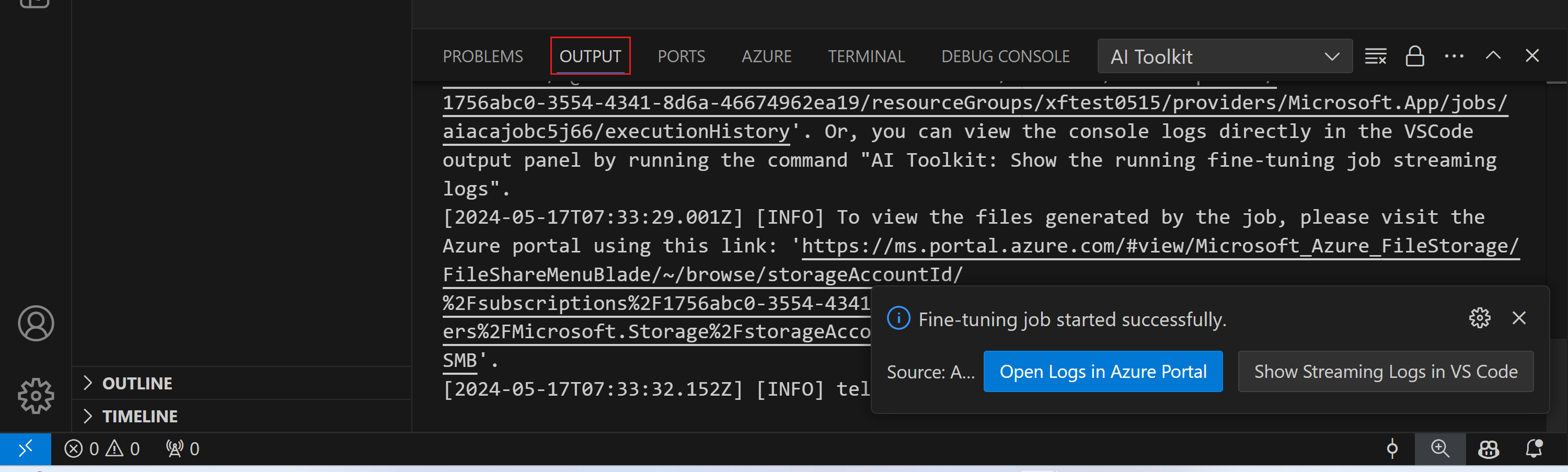
在微调作业触发后,您可以通过选择VSCode通知中的"在Azure门户中打开日志"按钮在Azure上查看日志。
或者,如果你已经打开了Azure门户,从"执行历史记录"面板找到Azure容器应用作业的历史记录。
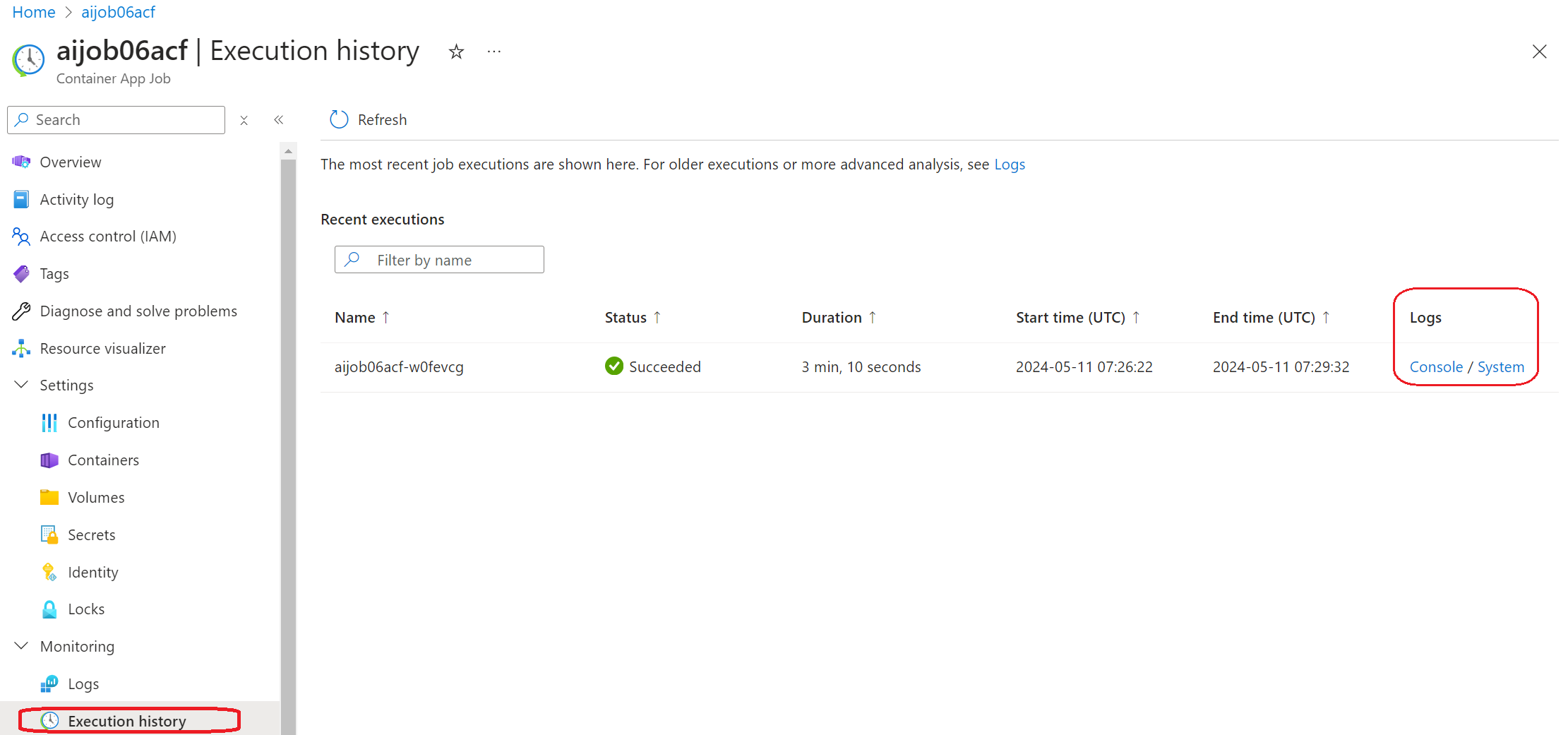
有两种日志,"控制台"和"系统"。
- 控制台日志是来自您的应用的消息,包括
标准错误输出和标准输出消息。这已经在流日志部分中看到。 - 系统日志是来自 Azure Container Apps 服务的消息,包括服务级别事件的状态。
要查看和查询您的日志,请选择"控制台"按钮并导航到日志分析页面,在此页面您可以查看所有日志并编写查询。
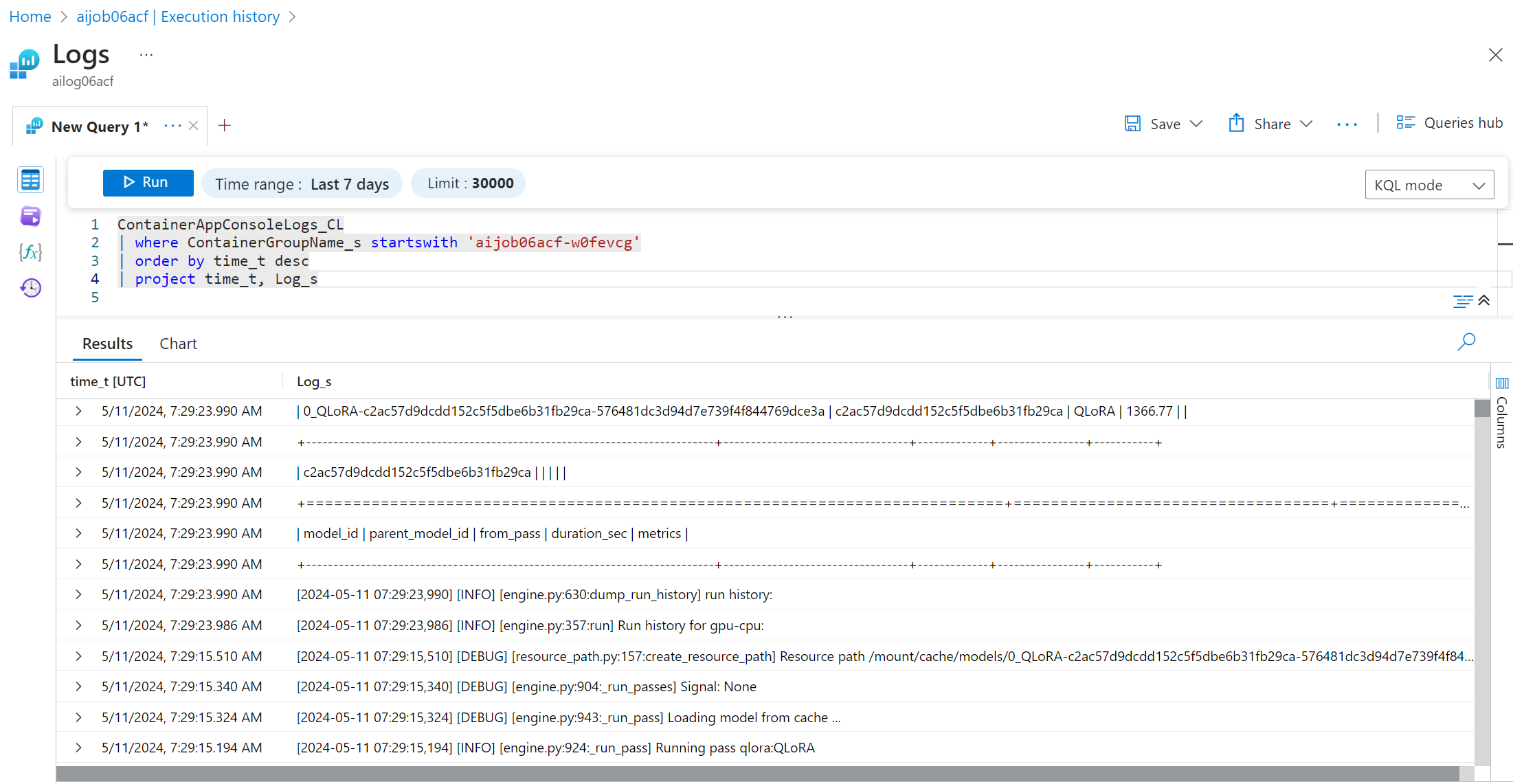
有关 Azure Container Apps 日志的更多信息,请参阅 Azure Container Apps 中的应用程序日志记录.
在 VSCode 中查看流媒体日志
在启动微调任务后,您还可以通过在VSCode通知中选择"在VS Code中显示流式日志"按钮在Azure上查看日志。
或者你可以运行命令AI 工具包:显示运行的微调作业流日志在命令面板中。

正在运行的微调作业的流式日志将显示在输出面板中。
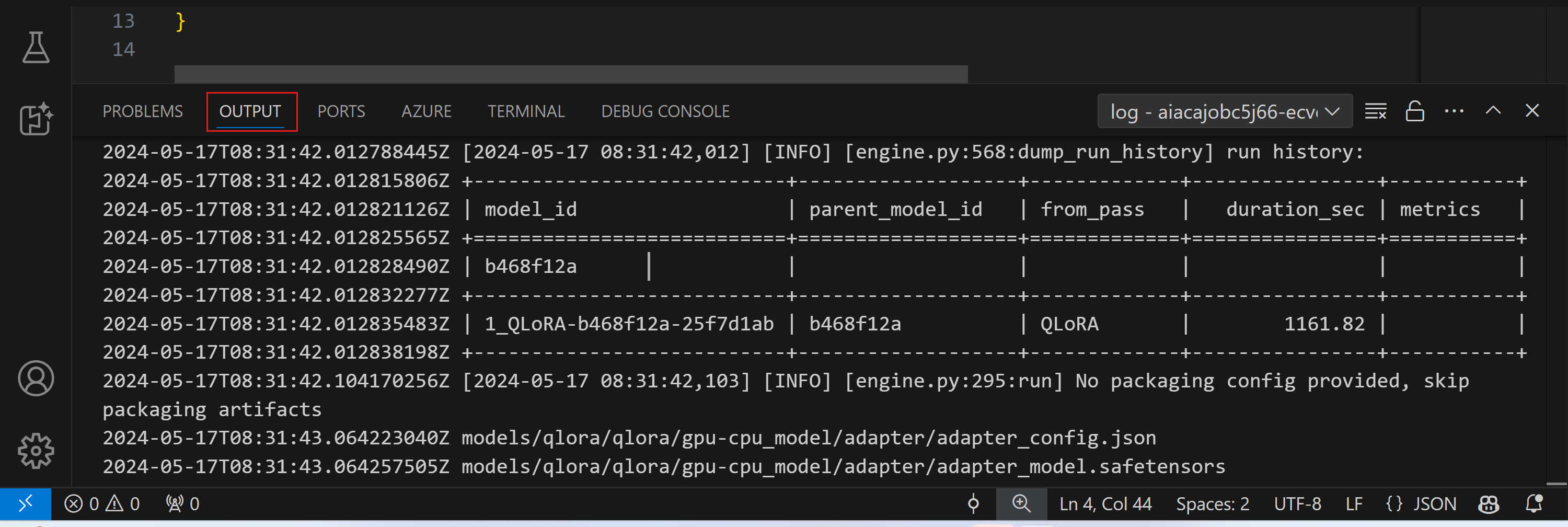
由于资源不足,该任务可能会排队。如果日志未显示,请等待一段时间,然后执行命令重新连接到流日志。 流日志可能会超时并断开连接。但是,可以通过再次执行命令进行重新连接。
使用微调后的模型进行推理
在远程环境中训练适配器后,使用简单的Gradio应用程序与模型进行交互。
提供 Azure 资源
类似于微调过程,您需要通过执行来设置用于远程推理的 Azure 资源AI 工具包:为推理提供 Azure 容器应用从命令面板中执行此操作。在设置过程中,您将被要求选择您的 Azure 订阅和资源组。

默认情况下,推理的订阅和资源组应与微调时使用的相同。推理将使用在微调步骤中生成的相同的 Azure Container App 环境,并访问存储在 Azure 文件中的模型和模型适配器。
推理部署
如果您希望修改推理代码或重新加载推理模型,请执行AI 工具包:部署用于推理命令。这将使您的最新代码与ACA同步并重启副本。

部署成功完成后,现在可以使用此端点对模型进行评估。
您可以通过选择 VSCode 通知中显示的 "转到推理端点" 按钮来访问推理 API。或者,可以在 ACA 应用端点在./infra/inference.config.json在输出面板中。

推理端点可能需要几分钟才能完全投入运行。
高级用法
微调项目组件
| 文件夹 | 目录 |
|---|---|
基础设施 |
包含远程操作所需的所有必要配置。 |
infra/provision/finetuning.parameters.json |
用于 Azure 资源微调的二头肌模板的参数。 |
infra/provision/finetuning.bicep |
包含用于微调的Azure资源供应模板。 |
infra/finetuning.config.json |
配置文件,由生成AI 工具包:为微调提供 Azure 容器应用作业命令。它被用作其他远程命令面板的输入。 |
在 Azure Container Apps 中配置微调秘密
Azure Container App Secrets 提供了一种安全的方式来在 Azure Container Apps 中存储和管理敏感数据,例如 HuggingFace 令牌和 Weights & Biases API 密钥。使用 AI 工具包的命令面板,您可以将这些密钥输入到已部署的 Azure 容器应用作业中(如存储在./finetuning.config.json) 这些秘密随后被设置为 环境变量 在所有容器中。
步骤
-
在命令面板中,输入并选择
AI 工具包:为微调添加 Azure 容器应用作业秘密
-
提供一个秘密名称和值


例如,如果你正在使用私有的HuggingFace数据集或需要Hugging Face访问控制的模型,请将你的HuggingFace令牌设置为环境变量
HF_令牌以避免在Hugging Face Hub上手动登录的需要。
设置完密钥后,您现在可以在 Azure Container App 中使用它。该密钥将设置在您的容器应用的环境变量中。
配置 Azure 资源以进行微调
本指南将帮助您配置AI 工具包:为微调提供 Azure 容器应用作业命令。
您可以在 中找到配置参数./infra/provision/finetuning.parameters.json文件。以下是详细信息:
| 参数 | 描述 |
|---|---|
默认命令 |
这是启动微调任务的默认命令。可以在中覆盖./infra/finetuning.config.json输入:. |
最大实例数量 |
此参数设置GPU实例的最大容量。 |
超时 |
这将Azure容器应用程序微调作业的超时时间设置为秒。默认值是10800,即3小时。如果Azure容器应用程序作业达到此超时时间,微调过程将停止。但是,检查点默认会保存,允许微调过程从上次的检查点恢复,而不是重新开始,如果再次运行。 |
位置 |
这是Azure资源部署的位置。默认值与所选资源组的位置相同。 |
存储账户名,文件共享名称 aca环境名称,aca环境存储名称,acaJobName输入: aca日志分析名称 |
这些参数用于为 Provision 命名 Azure 资源。您可以输入一个新的、未使用的资源名称来创建您自己的自定义命名资源,或者如果您愿意使用现有的 Azure 资源名称,您可以输入现有的 Azure 资源名称。 |
使用现有的 Azure 资源
如果您现有的 Azure 资源需要进行微调配置,您可以在./infra/provision/finetuning.parameters.json文件并运行AI 工具包:为微调提供 Azure 容器应用作业从命令面板执行。这将更新您指定的资源并创建任何缺失的资源。
例如,如果您有一个现有的 Azure 容器环境,您的./infra/finetuning.parameters.json应该看起来像这样:
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
...
"acaEnvironmentName": {
"value": "<your-aca-env-name>"
},
"acaEnvironmentStorageName": {
"value": null
},
...
}
}
手动配置
如果您更喜欢手动设置 Azure 资源,您可以使用提供的 bicep 文件在./基础设施/部署文件夹。如果您已经设置并配置了所有Azure资源,而没有使用AI Toolkit命令面板,您可以直接在finetune.config.json文件。
例如:
{
"SUBSCRIPTION_ID": "<your-subscription-id>",
"RESOURCE_GROUP_NAME": "<your-resource-group-name>",
"STORAGE_ACCOUNT_NAME": "<your-storage-account-name>",
"FILE_SHARE_NAME": "<your-file-share-name>",
"ACA_JOB_NAME": "<your-aca-job-name>",
"COMMANDS": [
"cd /mount",
"pip install huggingface-hub==0.22.2",
"huggingface-cli download <your-model-name> --local-dir ./model-cache/<your-model-name> --local-dir-use-symlinks False",
"pip install -r ./setup/requirements.txt",
"python3 ./finetuning/invoke_olive.py && find models/ -print | grep adapter/adapter"
]
}
模板中包含的推理组件
| 文件夹 | 目录 |
|---|---|
基础设施 |
包含远程操作所需的所有必要配置。 |
infra/提供/推理.参数.json |
用于为推理提供 Azure 资源的二头肌模板的参数。 |
infra/provision/inference.bicep |
包含用于为推理提供 Azure 资源的模板。 |
infra/inference.config.json |
配置文件,由生成AI 工具包:为推理提供 Azure 容器应用命令。它被用作其他远程命令面板的输入。 |
配置 Azure 资源供应
本指南将帮助您配置AI 工具包:为推理提供 Azure 容器应用命令。
您可以在 中找到配置参数./infra/provision/inference.parameters.json文件。以下是详细信息:
| 参数 | 描述 |
|---|---|
默认命令 |
这是启动网络API的命令。 |
最大实例数量 |
此参数设置GPU实例的最大容量。 |
位置 |
这是Azure资源部署的位置。默认值与所选资源组的位置相同。 |
存储账户名,文件共享名称 aca环境名称,aca环境存储名称,aca应用程序名称输入: aca日志分析名称 |
这些参数用于为 Provision 创建的 Azure 资源命名。默认情况下,它们将与微调资源名称相同。您可以输入一个新且未使用的资源名称来创建自定义命名的资源,或者如果您愿意使用已存在的 Azure 资源,可以输入该资源的名称。 |
使用现有的 Azure 资源
默认情况下,推理代码使用与微调相同的 Azure Container App 环境、存储帐户、Azure 文件共享和 Azure 日志分析。 仅用于推理 API 的单独 Azure Container App 被创建。
如果你在微调步骤中定制了 Azure 资源,或者希望使用你现有的 Azure 资源进行推理,请在 中指定它们的名称./infra/inference.parameters.json文件。然后,运行AI 工具包:为推理提供 Azure 容器应用从命令面板发出命令。这会更新任何指定的资源并创建任何缺失的资源。
例如,如果您有一个现有的 Azure 容器环境,您的./infra/finetuning.parameters.json应该看起来像这样:
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
...
"acaEnvironmentName": {
"value": "<your-aca-env-name>"
},
"acaEnvironmentStorageName": {
"value": null
},
...
}
}
手动配置
如果您更喜欢手动配置 Azure 资源,可以使用提供的 bicep 文件在./基础设施/部署文件夹。如果您已经通过 AI 工具包命令面板设置和配置了所有 Azure 资源,您可以直接在推理配置.json文件。
例如:
{
"订阅ID": "<你的订阅ID>",
"资源组名称": "<你的资源组名称>",
"存储账户名称": "<你的存储账户名称>",
"文件共享名称": "<你的文件共享名称>",
"ACA应用名称": "<你的ACA名称>",
"ACA应用端点": "<你的ACA端点>"
}
你所学到的
在本文中,您将学习如何:
- 为 VS Code 设置 AI 工具包,以支持在 Azure Container Apps 中进行微调和推理。
- 在 VS Code 的 AI 工具包中创建一个微调项目。
- 配置微调工作流程,包括数据集选择和训练参数。
- 运行微调工作流程以将预训练模型适应到您的特定数据集。
- 查看微调过程的结果,包括指标和日志。
- 使用示例笔记本进行模型推理和测试。
- 导出并与其他分享微调项目。
- 使用不同的数据集或训练参数重新评估模型。
- 处理失败的作业并调整配置以重新运行。
- 了解支持的模型及其微调要求。
- 使用 VS Code 的 AI 工具包来管理微调项目,包括提供 Azure 资源、运行微调作业以及部署模型进行推理。