在 VS Code 中使用 Data Wrangler 入门指南
Data Wrangler 是一个集成在 VS Code 和 VS Code Jupyter Notebooks 中的代码中心数据查看和清理工具。它提供了一个丰富的用户界面来查看和分析您的数据,显示有洞察力的列统计信息和可视化,并在您清理和转换数据时自动生成 Pandas 代码。
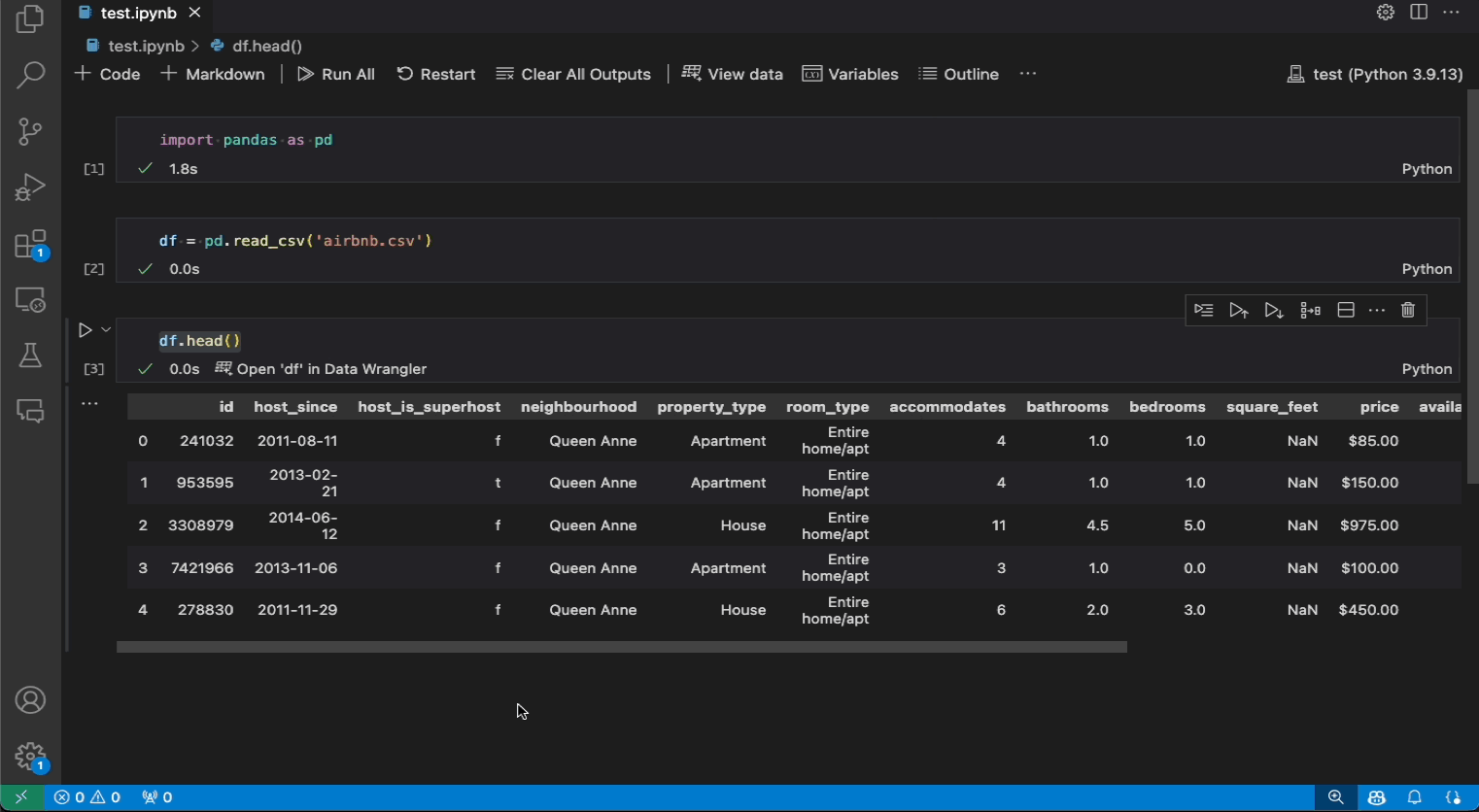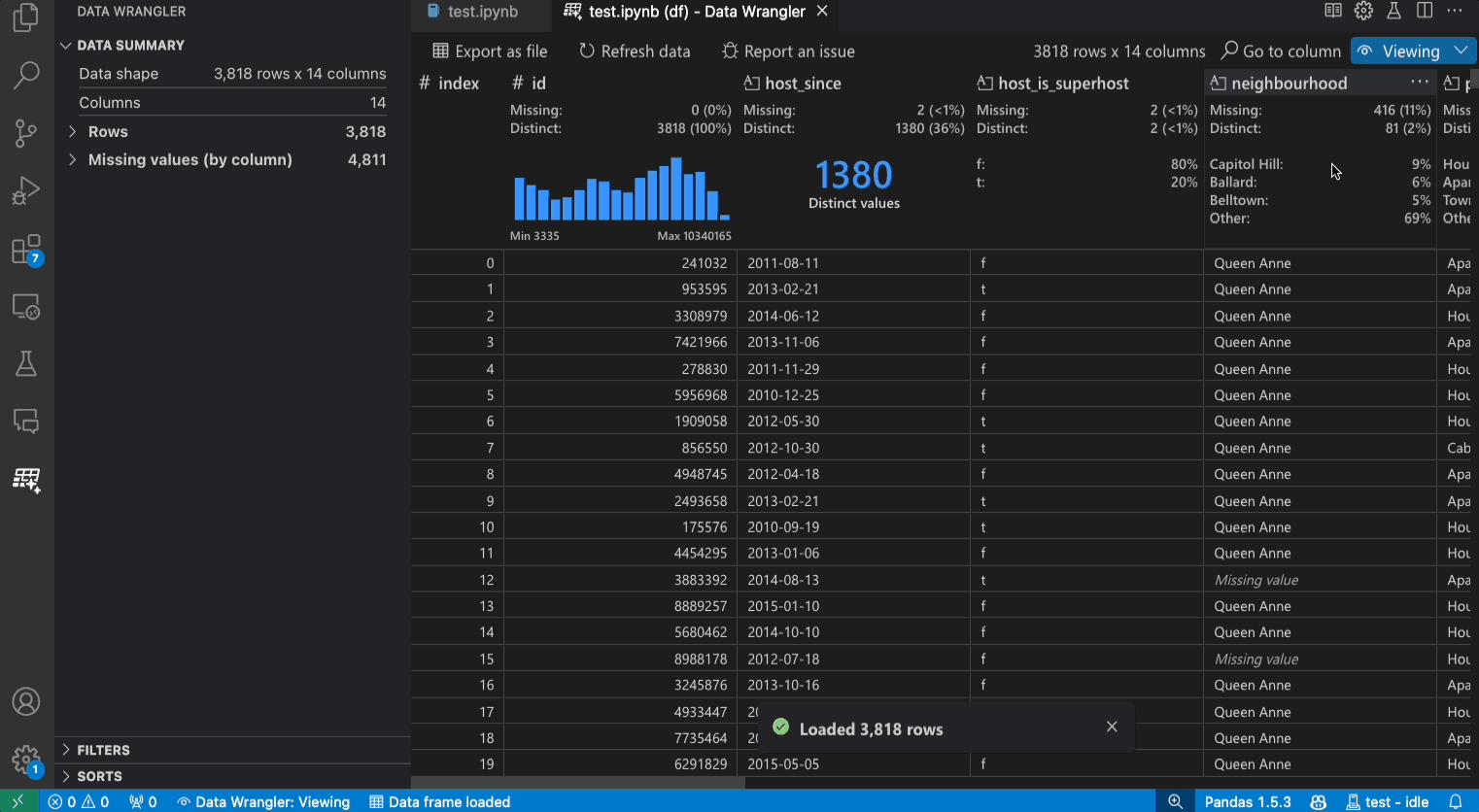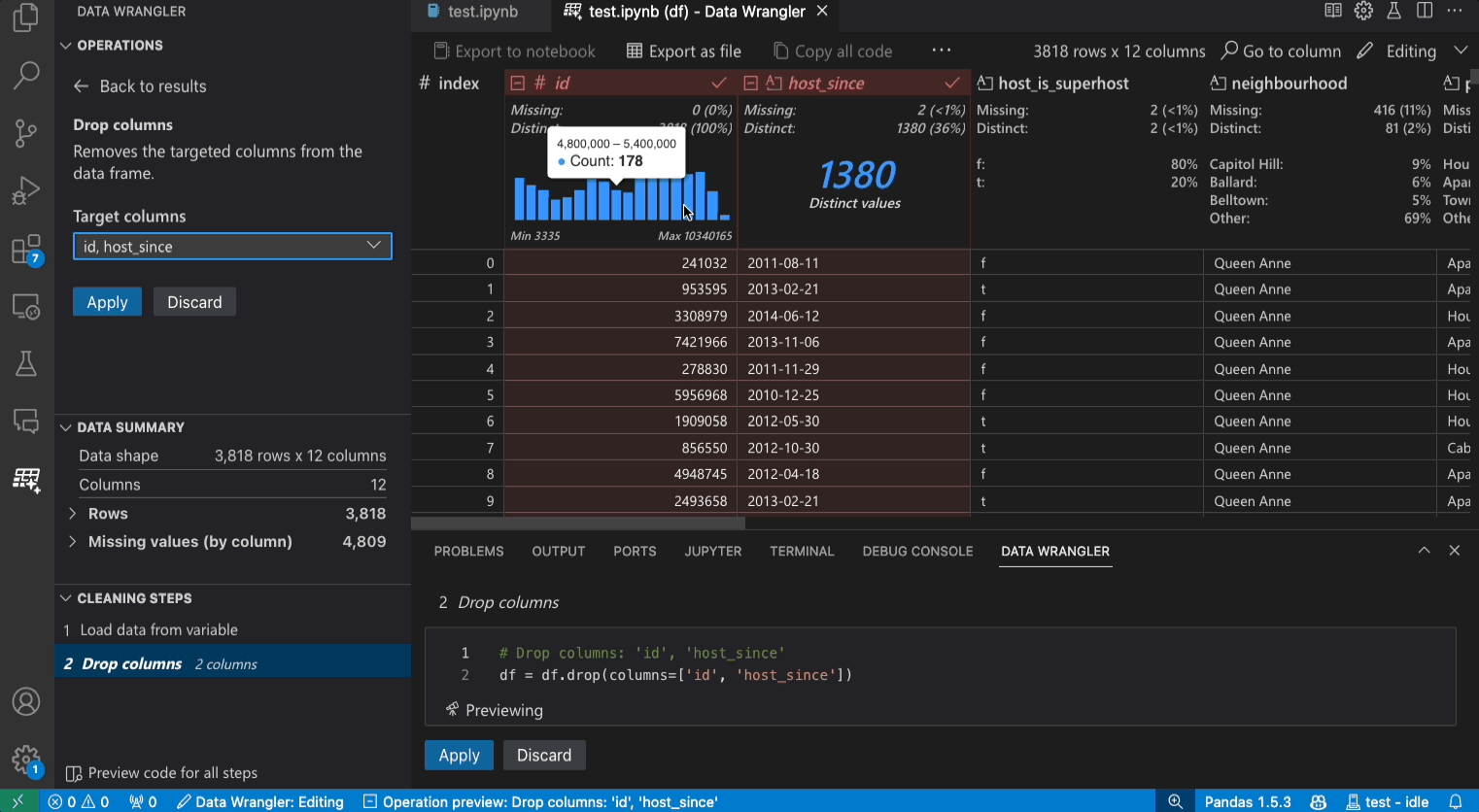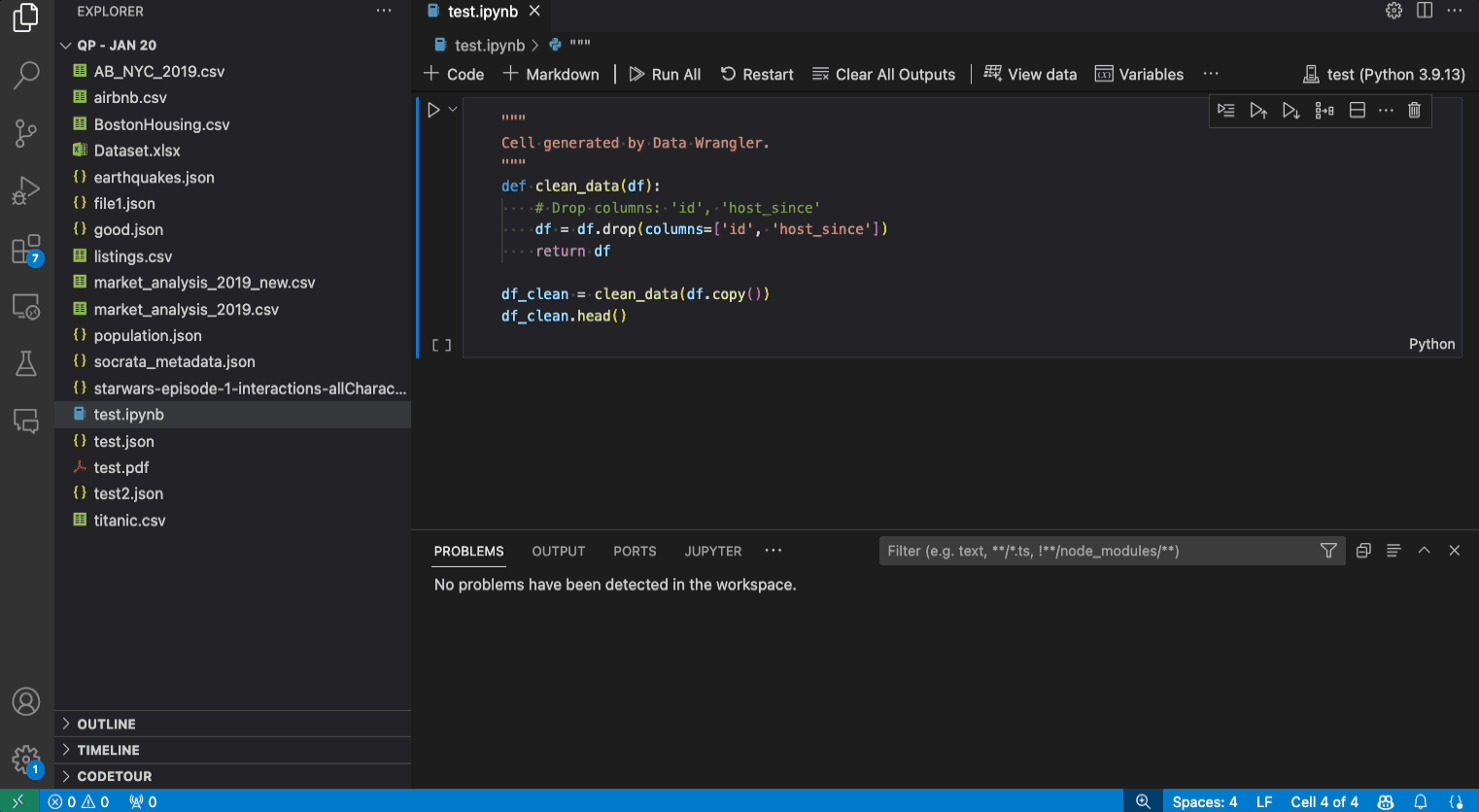
以下是从 notebook 中打开 Data Wrangler 的一个示例,以使用内置操作来分析和清理数据。然后将自动生成的代码导出回 notebook。
本文件涵盖如何:
- 安装和设置数据整理器
- 从笔记本中启动数据整理器
- 从数据文件启动数据整理器
- 使用数据整理器来探索您的数据
- 使用Data Wrangler对您的数据进行操作和清理
- 编辑并导出数据整理代码到一个笔记本
- 故障排除和提供反馈
设置您的环境
- 如果您还没有这样做,请安装Python。 重要: Data Wrangler仅支持 Python 3.8 或更高版本。
- 安装Visual Studio Code.
- 安装数据整理器扩展
当你第一次启动Data Wrangler时,它会问你想连接到哪个Python内核。它还会检查你的机器和环境,以确定是否安装了所需的Python包,例如Pandas。
以下是Python和Python包所需版本的列表,以及它们是否由Data Wrangler自动安装:
| 名字 | 最低要求版本 | 自动安装 |
|---|---|---|
| Python | 3.8 | 不 |
| 熊猫 | 0.25.2 | 是的 |
如果在你的环境中找不到这些依赖项,Data Wrangler 将尝试为你安装它们皮普如果 Data Wrangler 无法安装依赖项,最简单的解决方法是手动运行使用pip安装,然后再次启动Data Wrangler。这些依赖项是Data Wrangler所必需的,以便它可以生成Python和Pandas代码。
开放数据整理师
无论何时你在Data Wrangler中,你都处于一个受限的环境中,这意味着你可以安全地探索和转换数据。在你明确导出更改之前,原始数据集不会被修改。
从 Jupyter Notebook 启动数据 Wrangler
有三种方法可以从前端 Notebook 启动 Data Wrangler
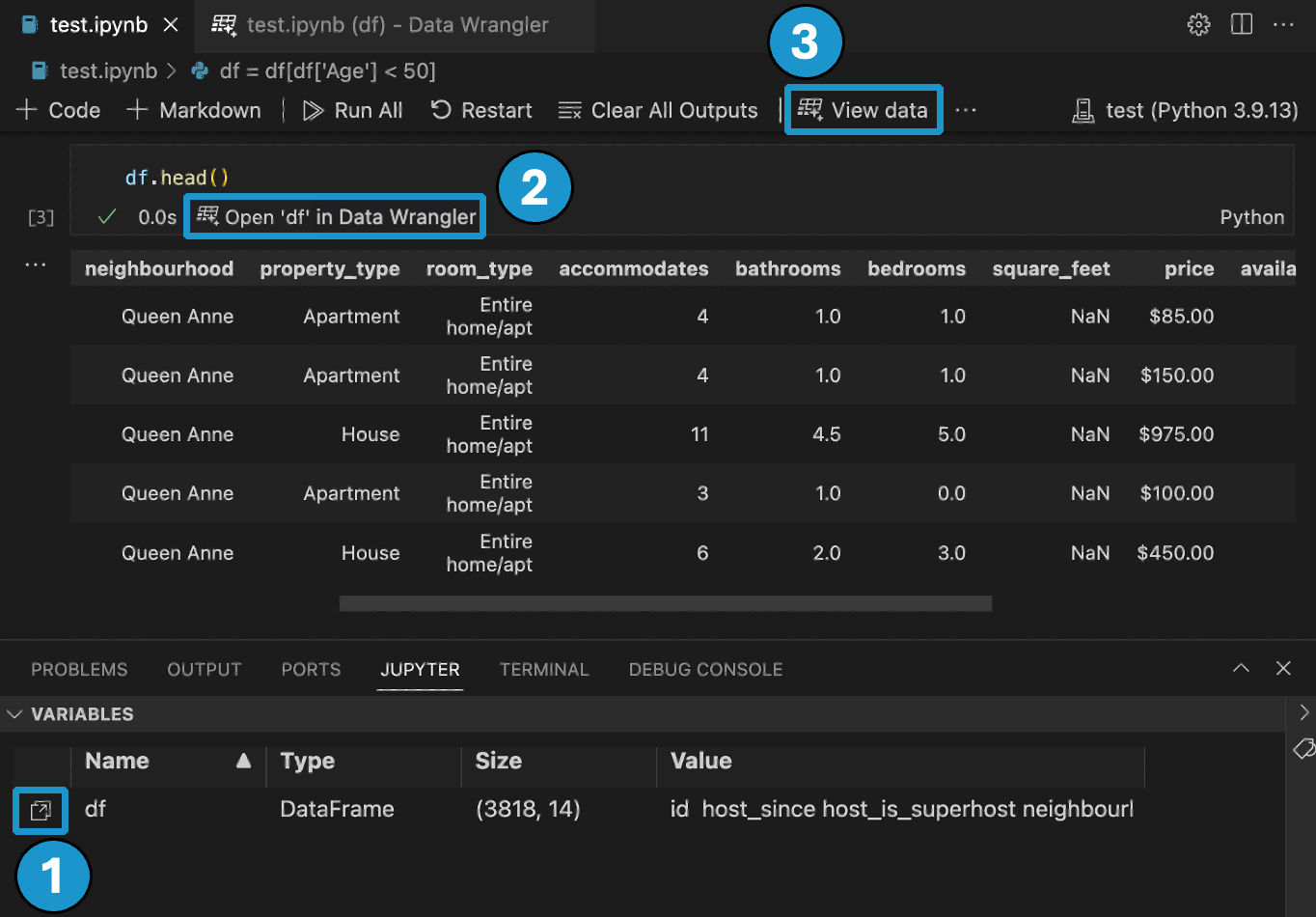
- 在Jupyter > 变量面板中,任何支持的数据对象旁边,您都可以看到一个启动Data Wrangler的按钮。
- 如果你的笔记本中有Pandas数据框,现在你可以在运行输出数据框的代码后,在单元格底部看到一个在数据整理器中打开“df”按钮(其中“df”是你的数据框的变量名)。这包括1)
df.head(), 2)df.tail(), 3)显示(df), 4)打印(df), 5)输入:df输入:. - 在笔记本工具栏中,选择“查看数据”,会列出笔记本中支持的所有数据对象。然后,您可以选择要在一个数据整理器中打开的变量。
直接从文件中启动数据整理器
你也可以直接从本地文件(例如一个 )启动 Data Wrangler输入:.csv) 要做到这一点,请在 VS Code 中打开包含您要打开的文件的任何文件夹。在文件资源管理器视图中,右键单击该文件并点击在数据整理器中打开.
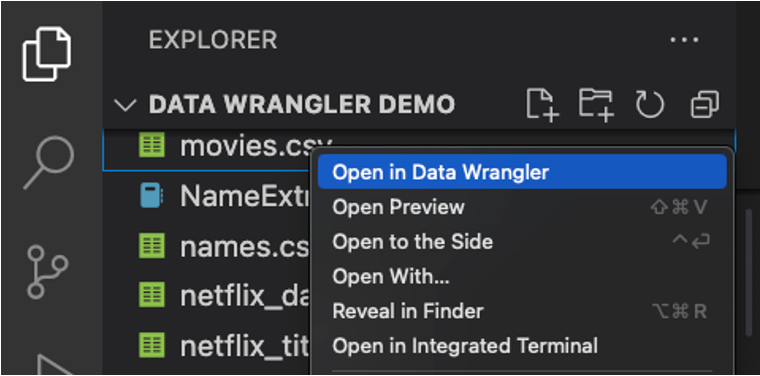
Data Wrangler目前支持以下文件类型
输入:.csv输入:/.tsv输入:.xls输入:/.xlsx.parquet
根据文件类型,您可以指定分隔符和/或工作表。
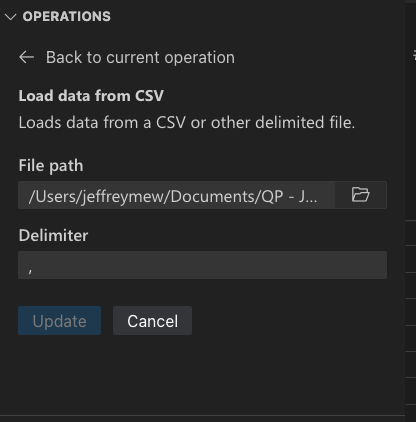
您还可以将这些文件类型默认设置为使用Data Wrangler打开。
UI 之旅
Data Wrangler在处理数据时有两种模式。每个模式的详细信息在下面的各节中解释。
- 查看模式: 查看模式优化了界面,使您可以快速查看、筛选和排序您的数据。此模式非常适合对数据集进行初步探索。
- 编辑模式: 编辑模式优化了界面,使您可以对数据集应用转换、清理或修改。当您在界面中应用这些转换时,Data Wrangler会自动生成相关的Pandas代码,这可以导出到您的笔记本中以供重复使用。
注意:默认情况下,Data Wrangler以查看模式打开。您可以在设置编辑器中更改此行为。输入:.

查看模式界面
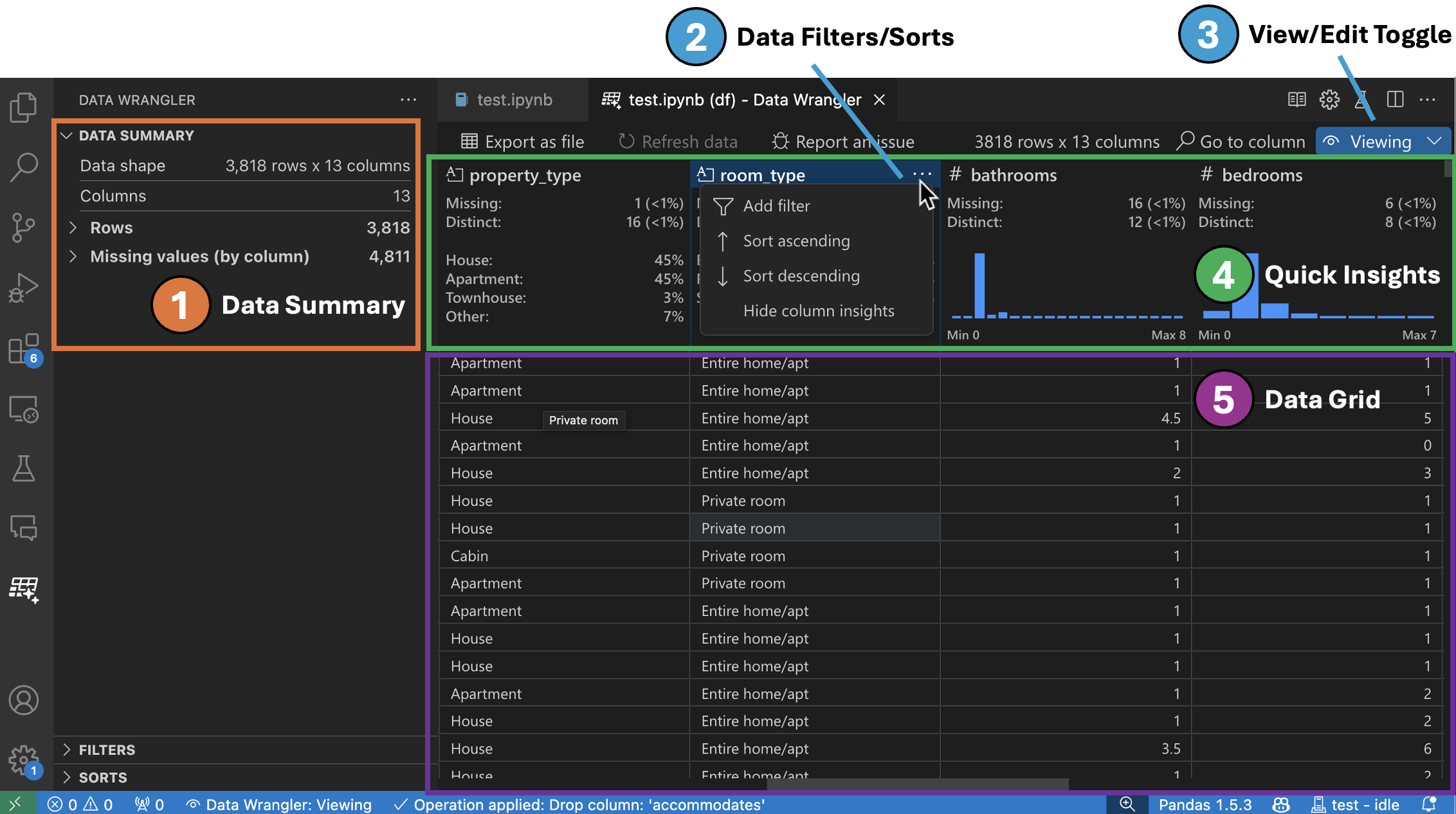
-
数据概要面板显示了您的整个数据集或选定列的详细摘要统计数据。
-
您可以从列标题菜单中对任何数据过滤器/排序应用到该列上。
-
在 查看 和 编辑 模式之间切换,以访问内置数据操作。
-
快速见解标题是您可以快速查看每个列的有价值信息的地方。根据列的数据类型,快速见解显示数据的分布或数据点的频率,以及缺失和不同的值。
-
数据网格提供了一个可滚动的面板,您可以在此查看整个数据集。
编辑模式界面
切换到编辑模式会在Data Wrangler中启用额外的功能和用户界面元素。在以下截图中,我们使用Data Wrangler将最后一列中的缺失值替换为该列的中位数。
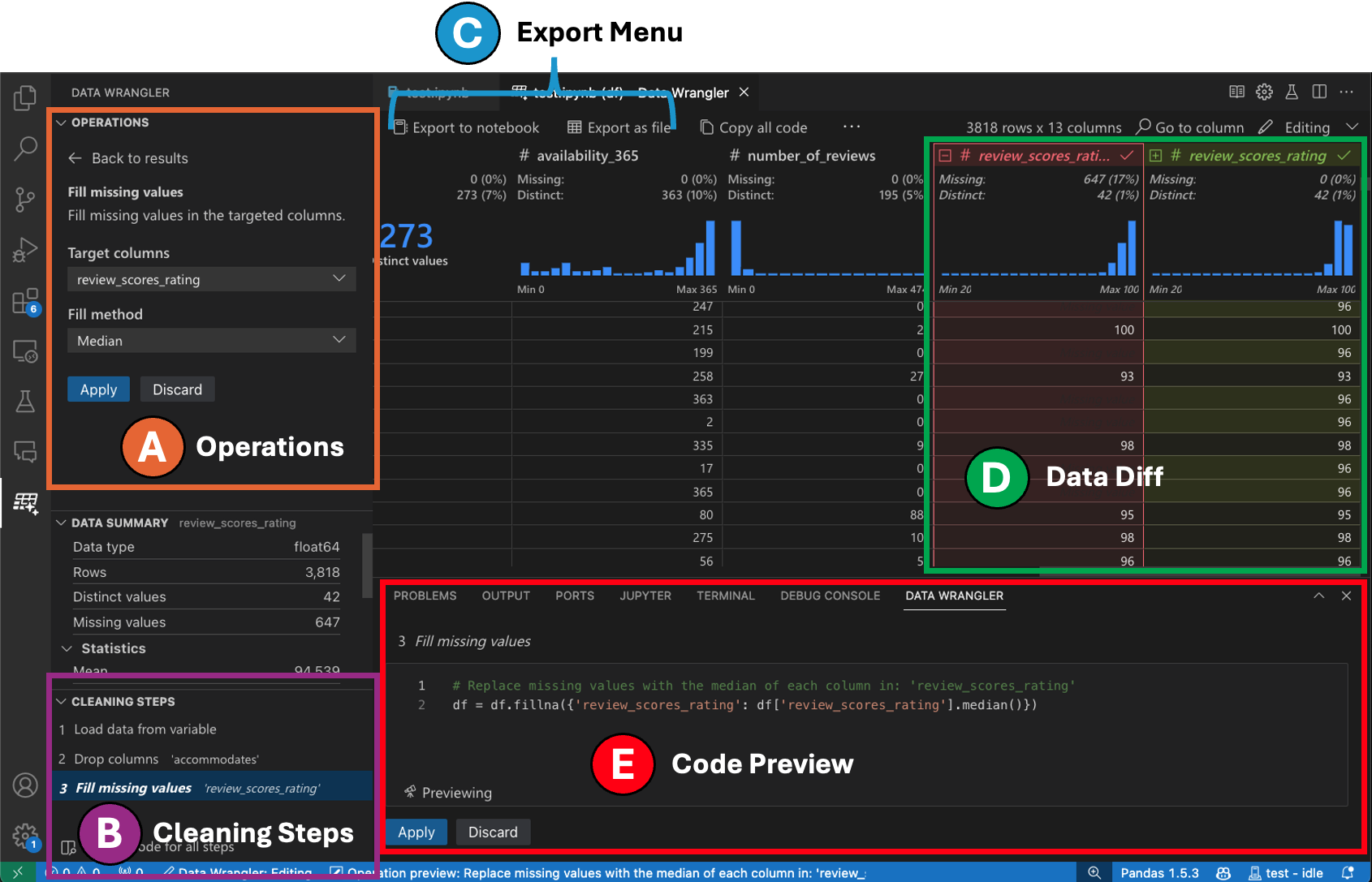
-
操作面板是您可以搜索Data Wrangler的所有内置数据操作的地方。这些操作按类别组织。
-
清理步骤面板显示了之前应用的所有操作列表。它使用户能够撤销特定操作或编辑最近的操作。选择一个步骤将在数据差异视图中突出显示该操作的更改,并显示与此操作相关的生成代码。
-
导出菜单允许您将代码导出回Jupyter Notebook或导出数据到新文件。
-
当你选择了一个操作并预览其对数据的影响时,网格上会覆盖一个数据差异视图,显示你对数据所做的更改。
-
代码预览部分显示了在选择操作时Data Wrangler生成的Python和Pandas代码。当未选择任何操作时,它保持为空。您可以编辑生成的代码,这将导致数据网格突出显示对数据的影响。
数据整理操作
内置的数据整理操作可以从操作面板中选择。
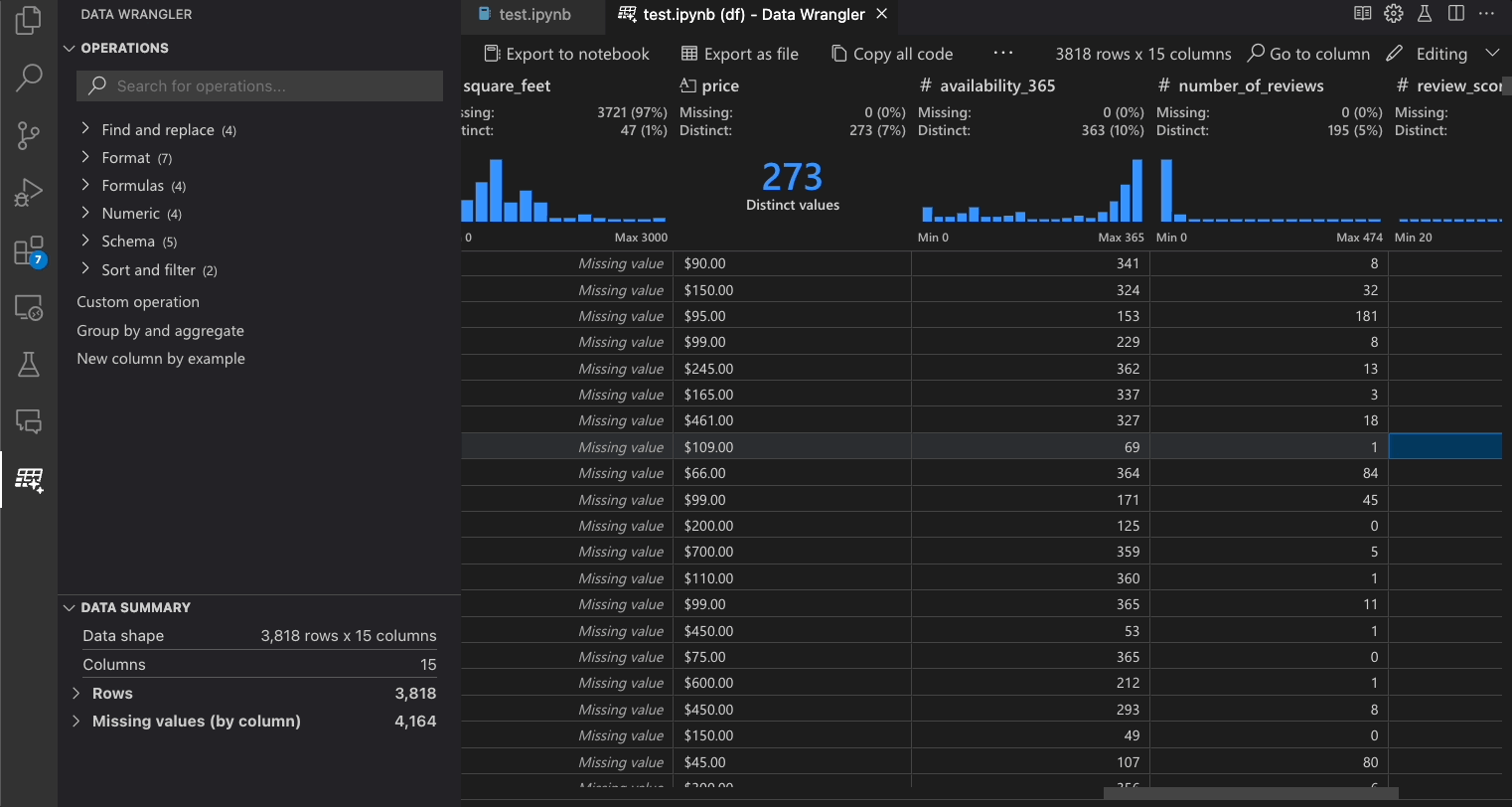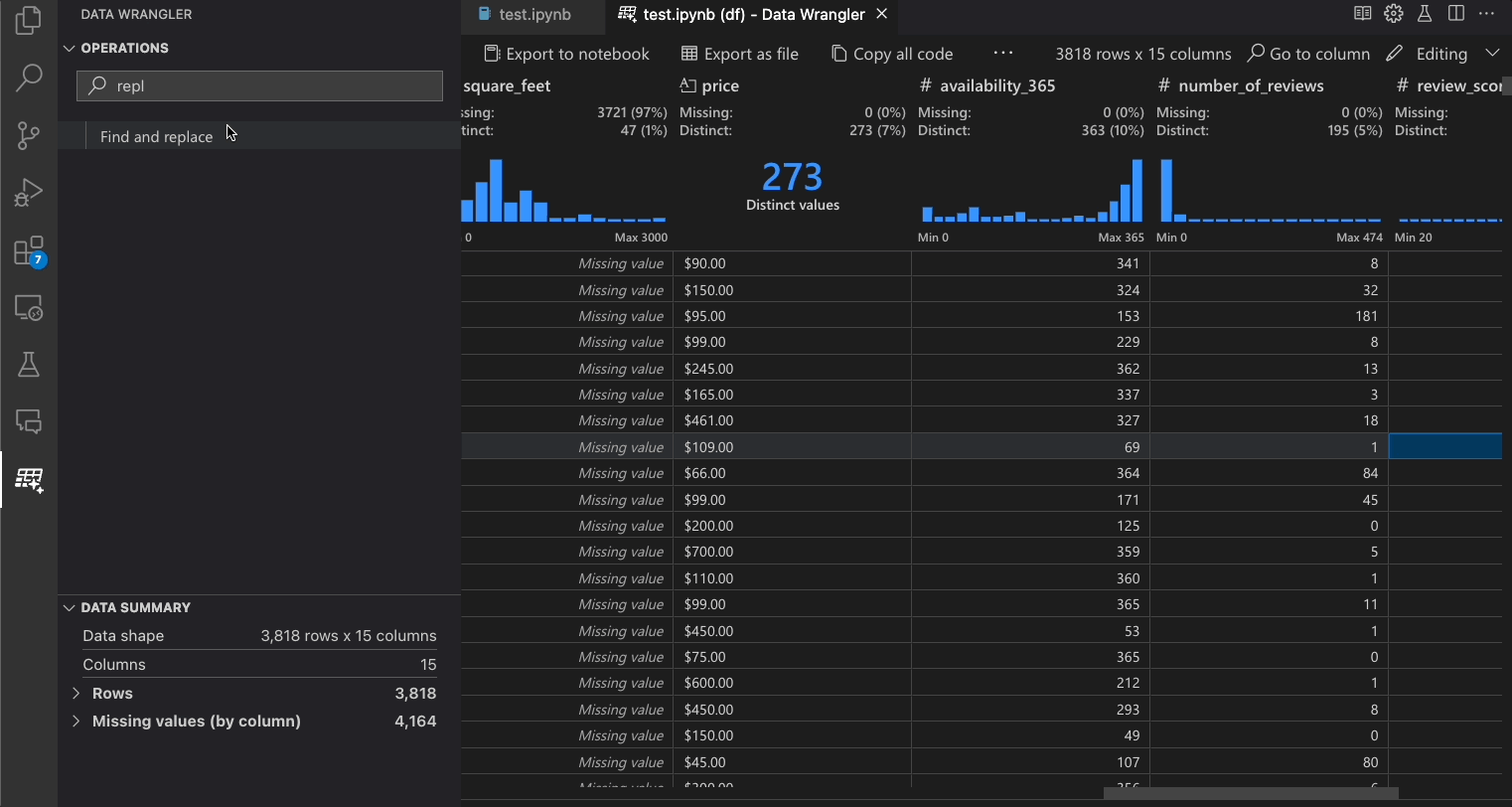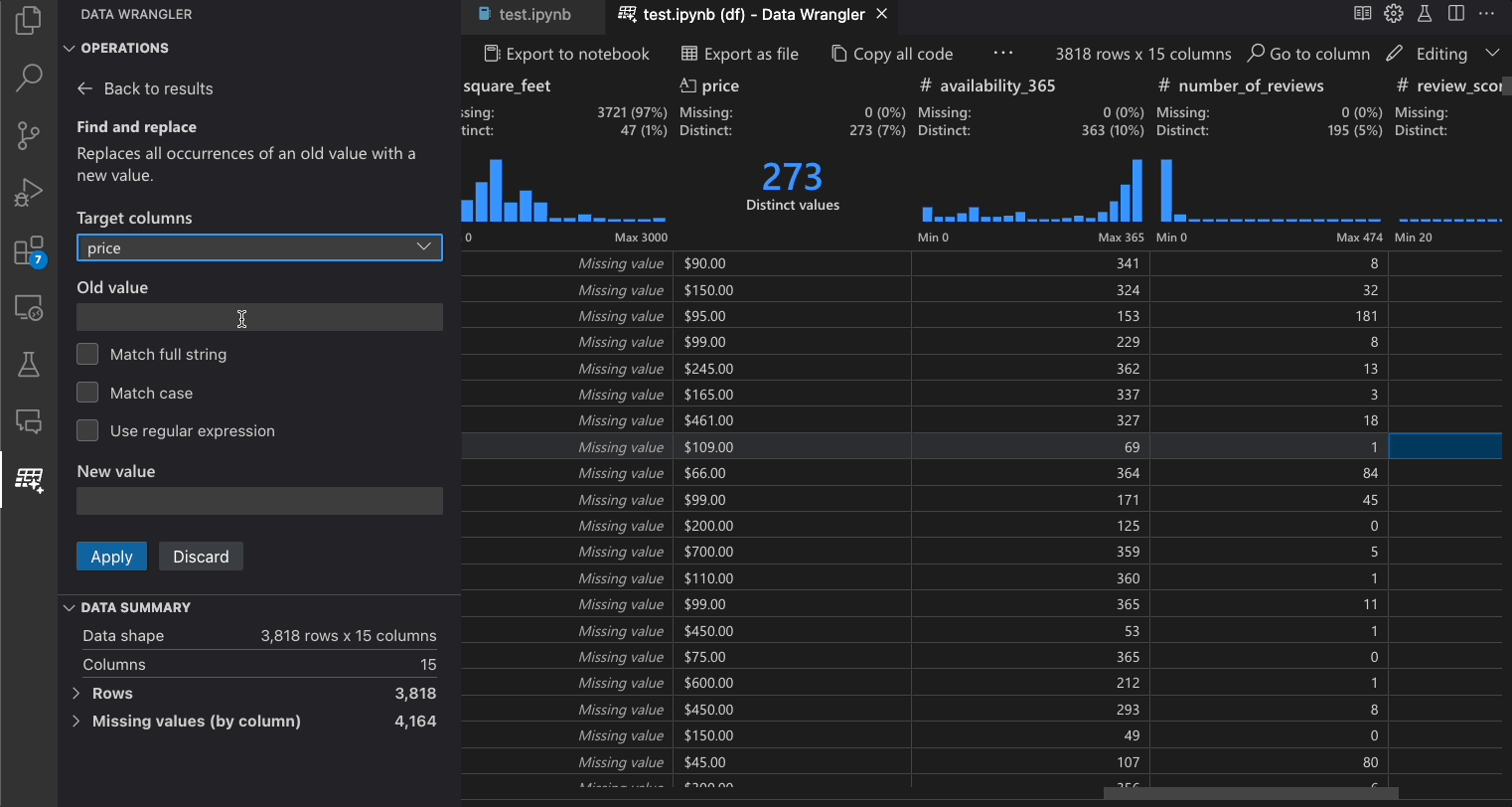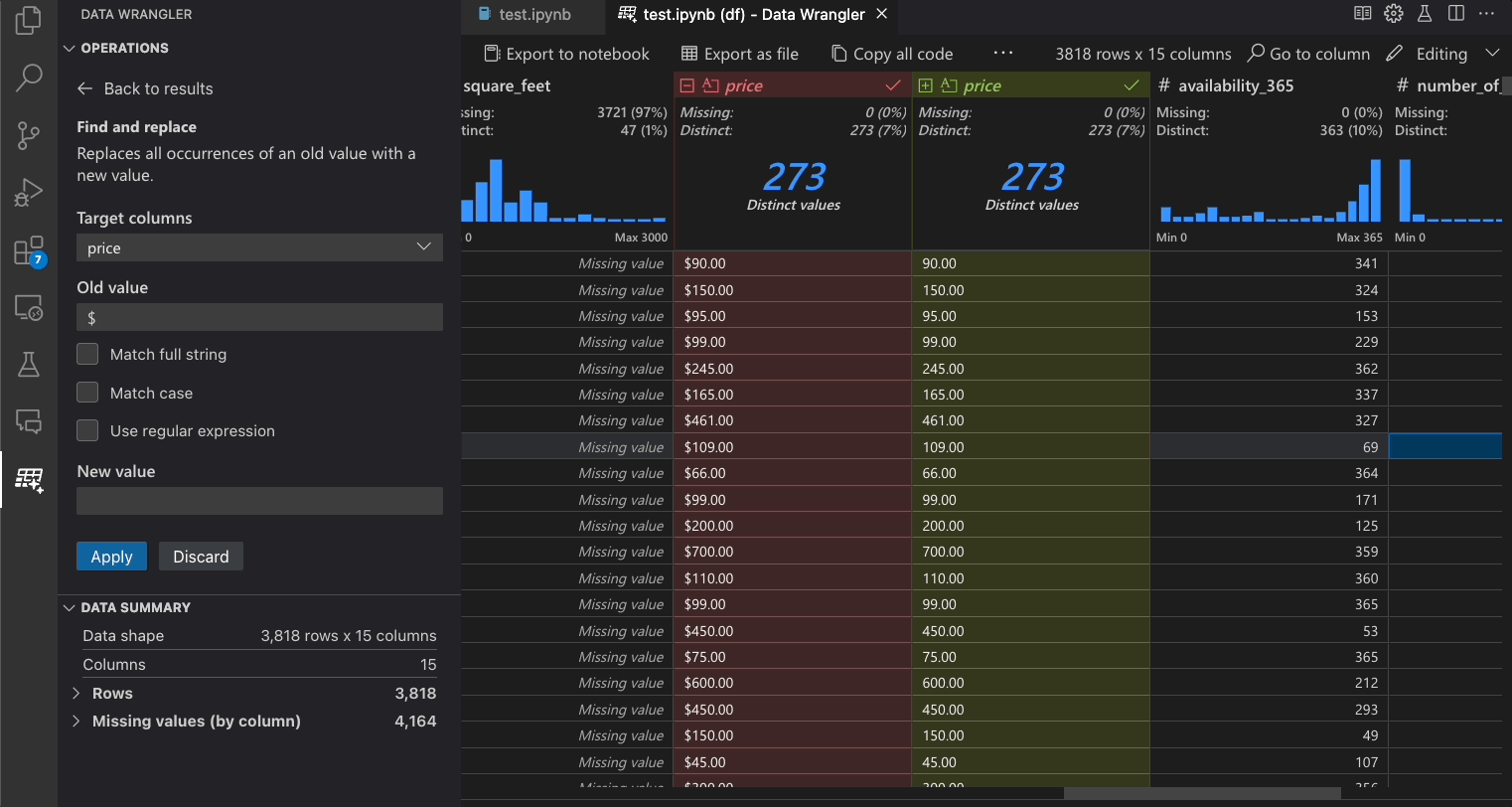
下表列出了Data Wrangler初始发布版本中当前支持的Data Wrangler操作。我们计划在不久的将来添加更多操作。
| 操作 | 描述 |
|---|---|
| 排序 | 按列升序或降序排序 |
| 过滤器 | 根据一个或多个条件筛选行 |
| 计算文本长度 | 创建一个新列,其值为文本列中每个字符串值的长度。 |
| 独热编码 | 将分类数据拆分为每个类别一个新的列 |
| 多标签二值化器 | 使用分隔符将分类数据拆分为每个类别一个新的列 |
| 从公式创建列 | 使用自定义的Python公式创建一列 |
| 更改列类型 | 更改列的数据类型 |
| 删除列 | 删除一个或多个列 |
| 选择列 | 选择一个或多个列保留,其余列删除 |
| 重命名列 | 重命名一个或多个列 |
| 克隆柱 | 创建一个或多个列的副本 |
| 删除缺失值 | 删除包含缺失值的行 |
| 删除重复行 | 删除所有在一个或多个列中具有重复值的行 |
| 填充缺失值 | 用新值替换缺失值的单元格 |
| 查找和替换 | 用匹配模式替换单元格 |
| 按列分组并聚合 | 按列分组并聚合结果 |
| 去除空白字符 | 移除文本开头和结尾的空白字符 |
| 拆分文本 | 根据用户定义的分隔符将一列拆分为多列 |
| 将第一个字符大写 | 将第一个字符转换为大写,其余字符转换为小写 |
| 将文本转换为小写 | 将文本转换为小写 |
| 将文本转换为大写 | 将文本转换为大写 |
| 字符串示例转换 | 自动对您提供的示例中检测到的模式进行字符串转换 |
| 通过示例进行日期时间格式化 | 自动对您提供的示例中检测到的日期时间格式进行格式化 |
| 新栏目:以例论事 | 当从您提供的示例中检测到模式时,自动生成一列。 |
| 刻度最小/最大值 | 将数值列缩放至最小值和最大值之间 |
| 圆形 | 将数字四舍五入到指定的小数位数 |
| 向下取整 | 将数字向下舍入到最接近的整数 |
| 向上取整 | 将数字四舍五入到最接近的整数 |
| 自定义操作 | 根据示例和现有列的推导自动创建新列 |
如果有一些操作在 Data Wrangler 中缺失,而你希望 Data Wrangler 能够支持这些操作,请在我们的 Data Wrangler GitHub 仓库 提出功能请求。
修改先前的步骤
生成的代码的每一步都可以通过清理步骤面板进行修改。首先,选择您要修改的步骤。然后,当您更改操作(通过代码或操作面板)时,数据视图中会突出显示您更改的影响。
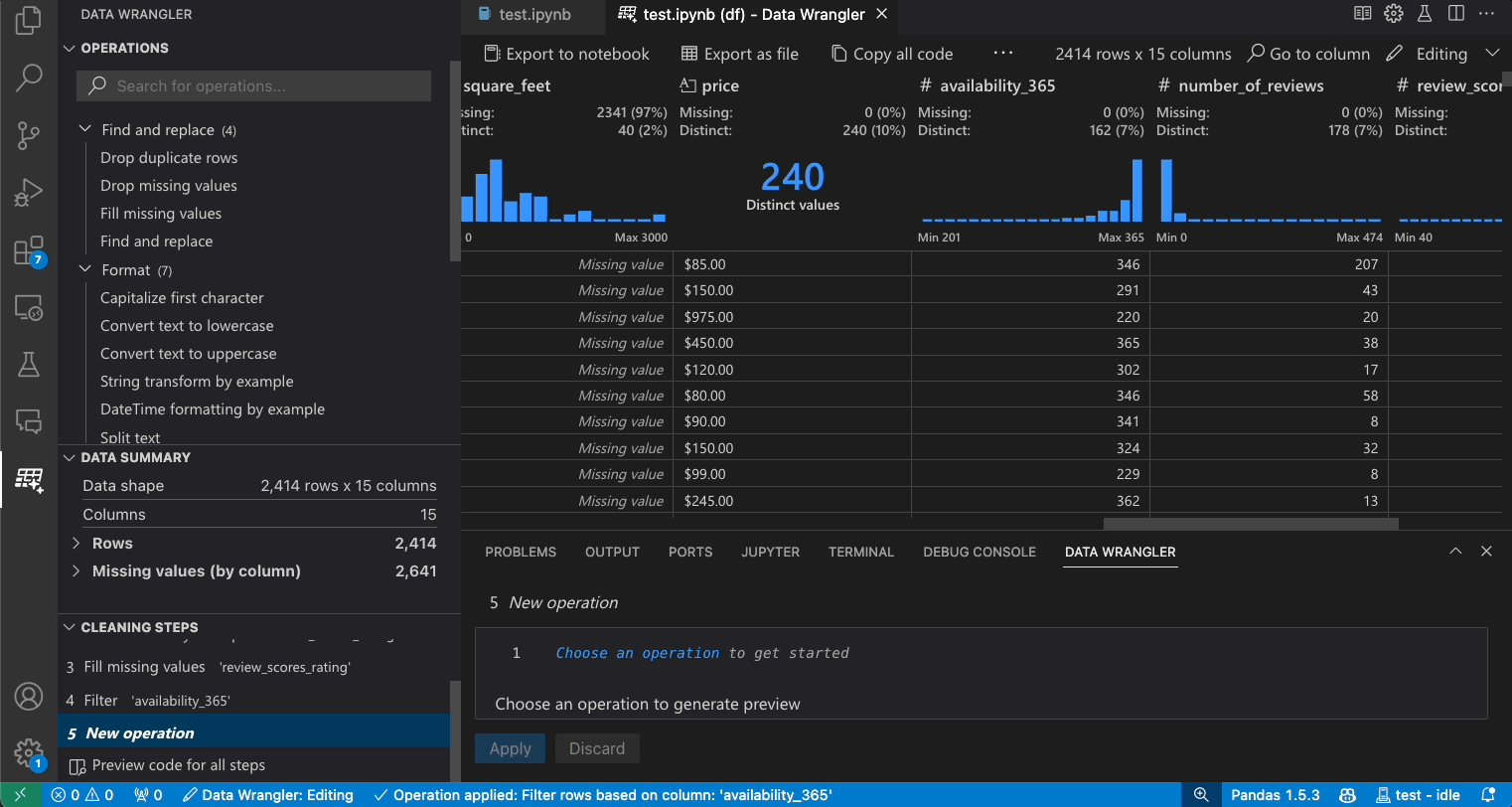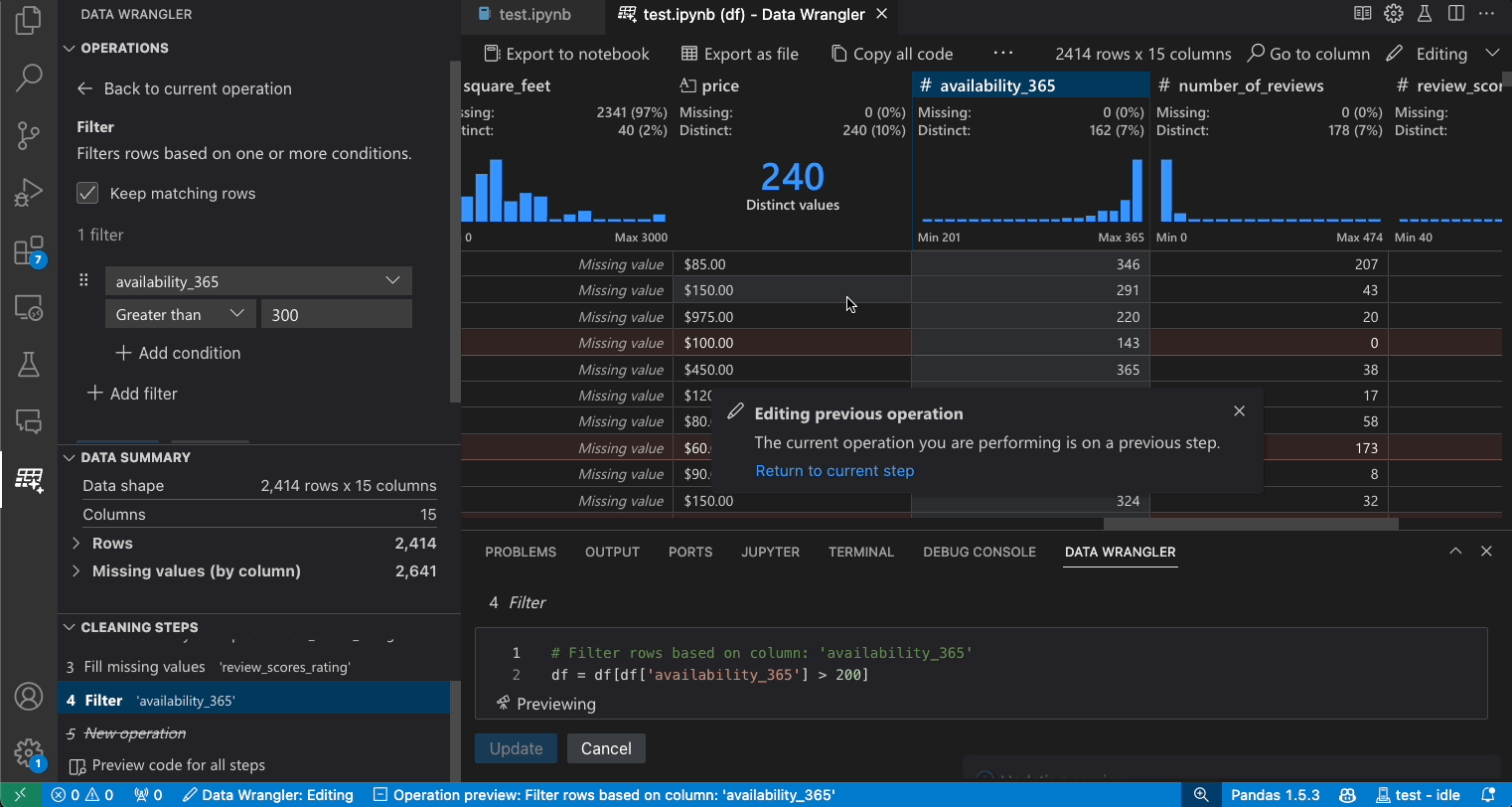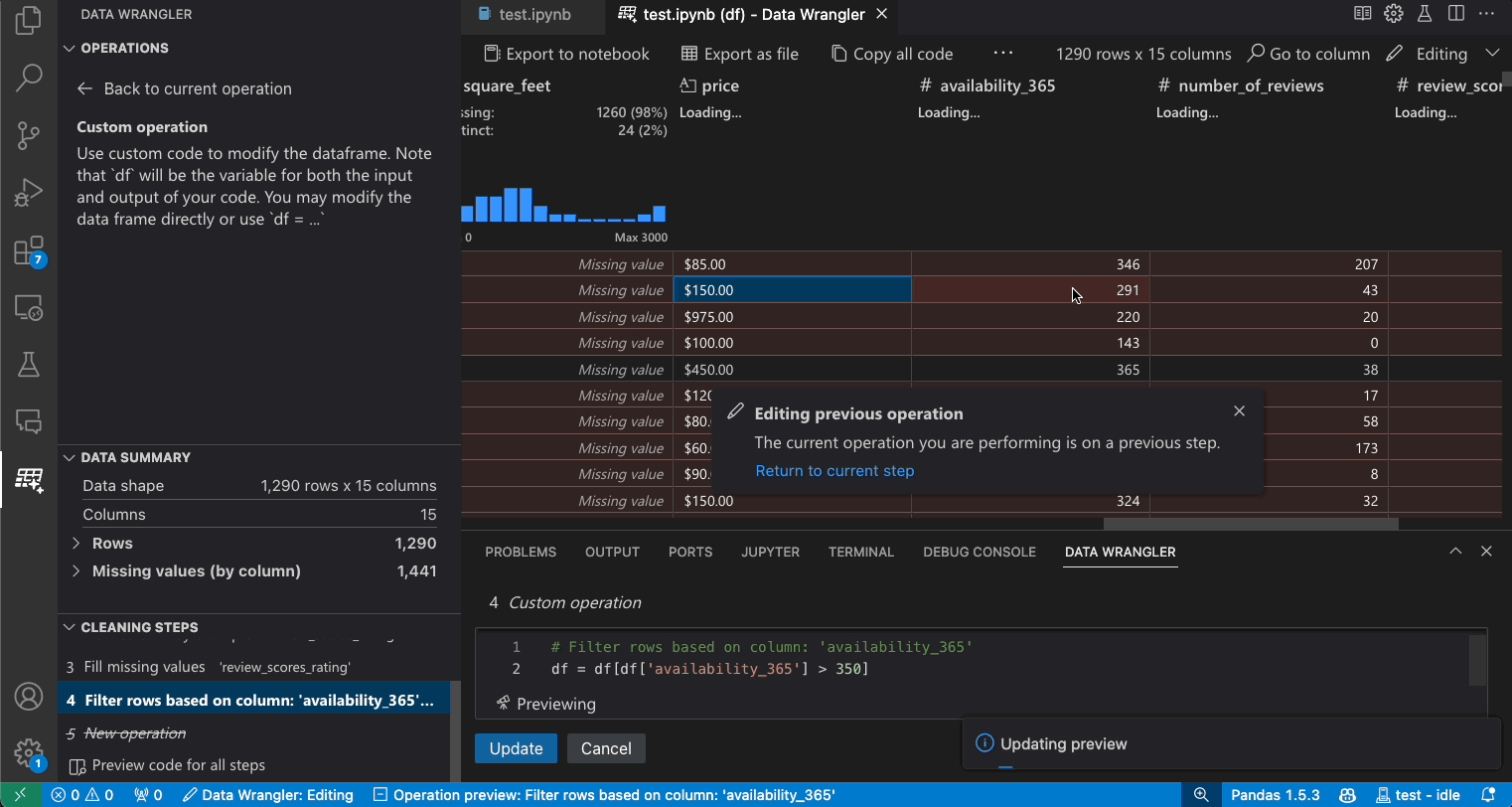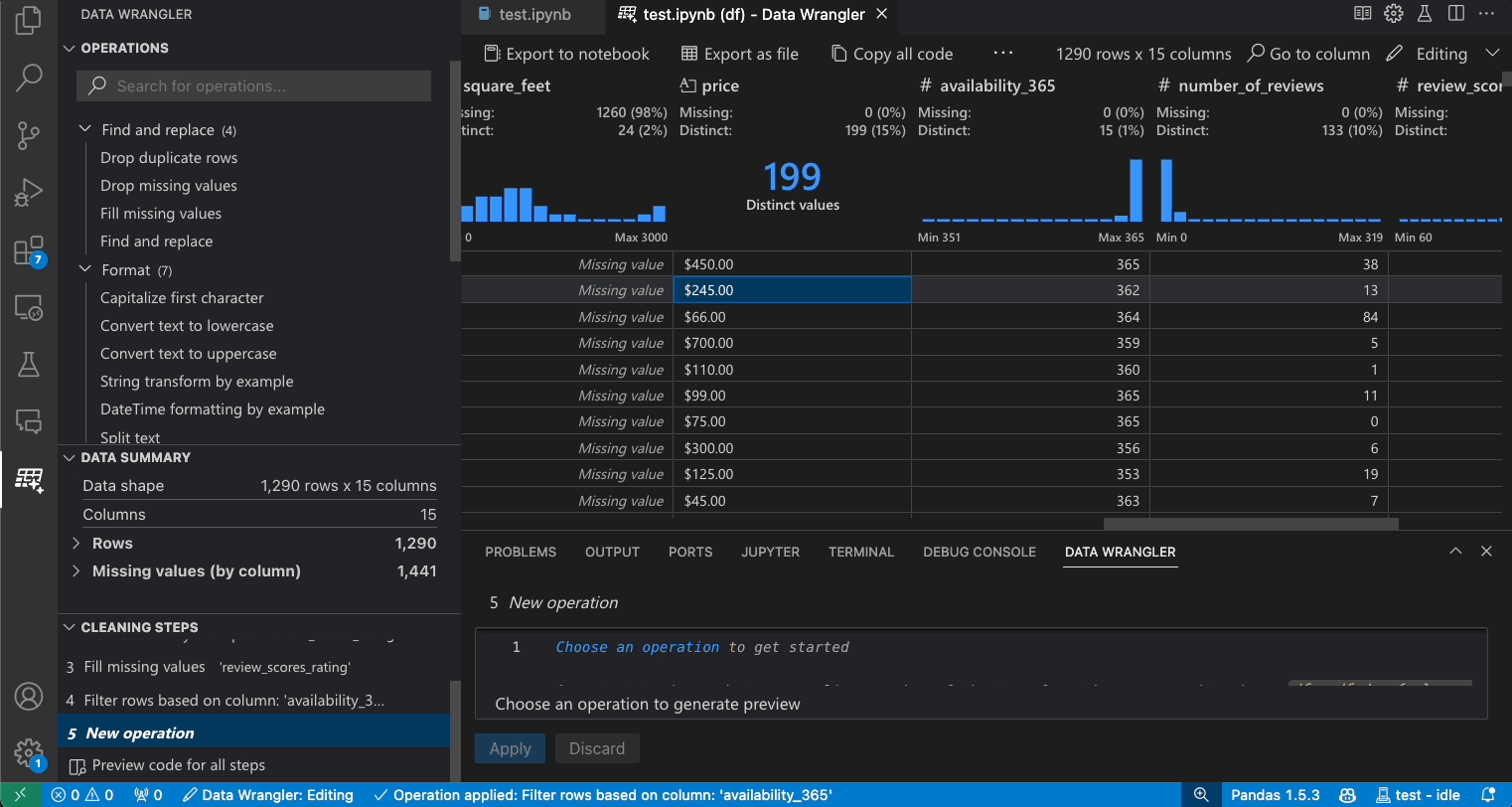
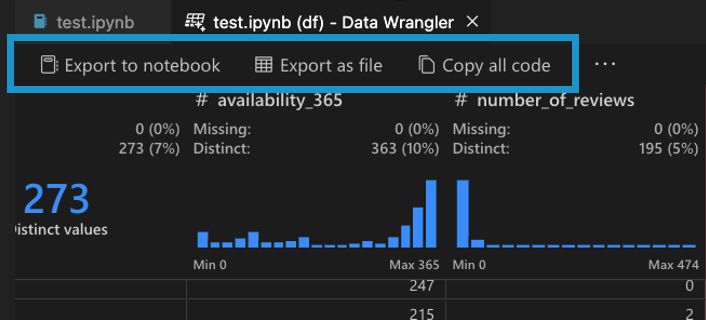
编辑和导出代码
一旦你完成了在Data Wrangler中的数据清理步骤,有三种方法可以将清理后的数据集导出从Data Wrangler。
- 将代码导出回Notebook并退出:这会在你的Jupyter Notebook中创建一个新的单元格,包含你生成的所有数据清理代码,并将其打包成一个Python函数。
- 将数据导出到文件: 这将把清理后的数据集保存为新的CSV或Parquet文件到您的机器上。
- 将代码复制到剪贴板: 这将复制Data Wrangler为数据清理操作生成的所有代码。
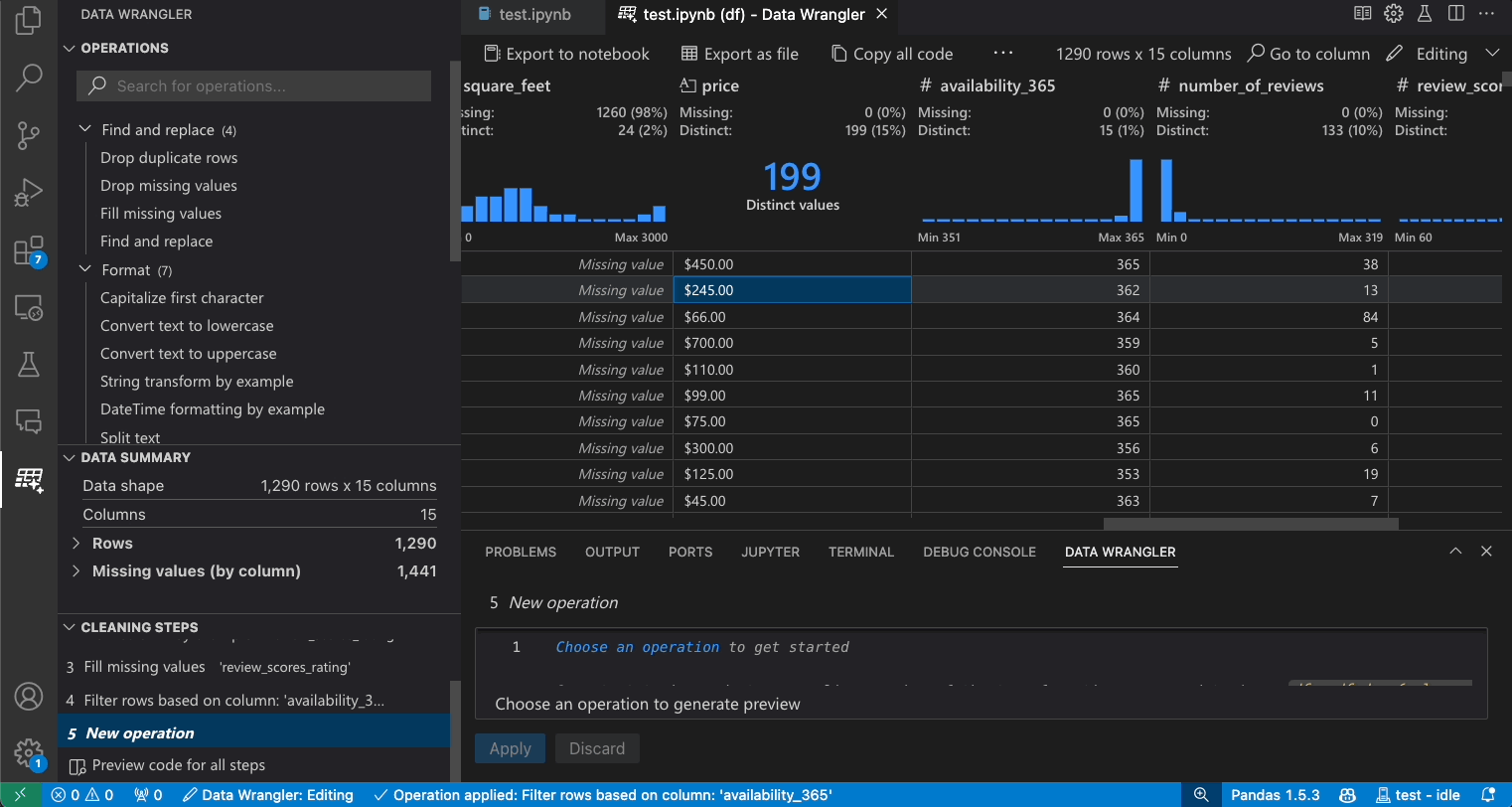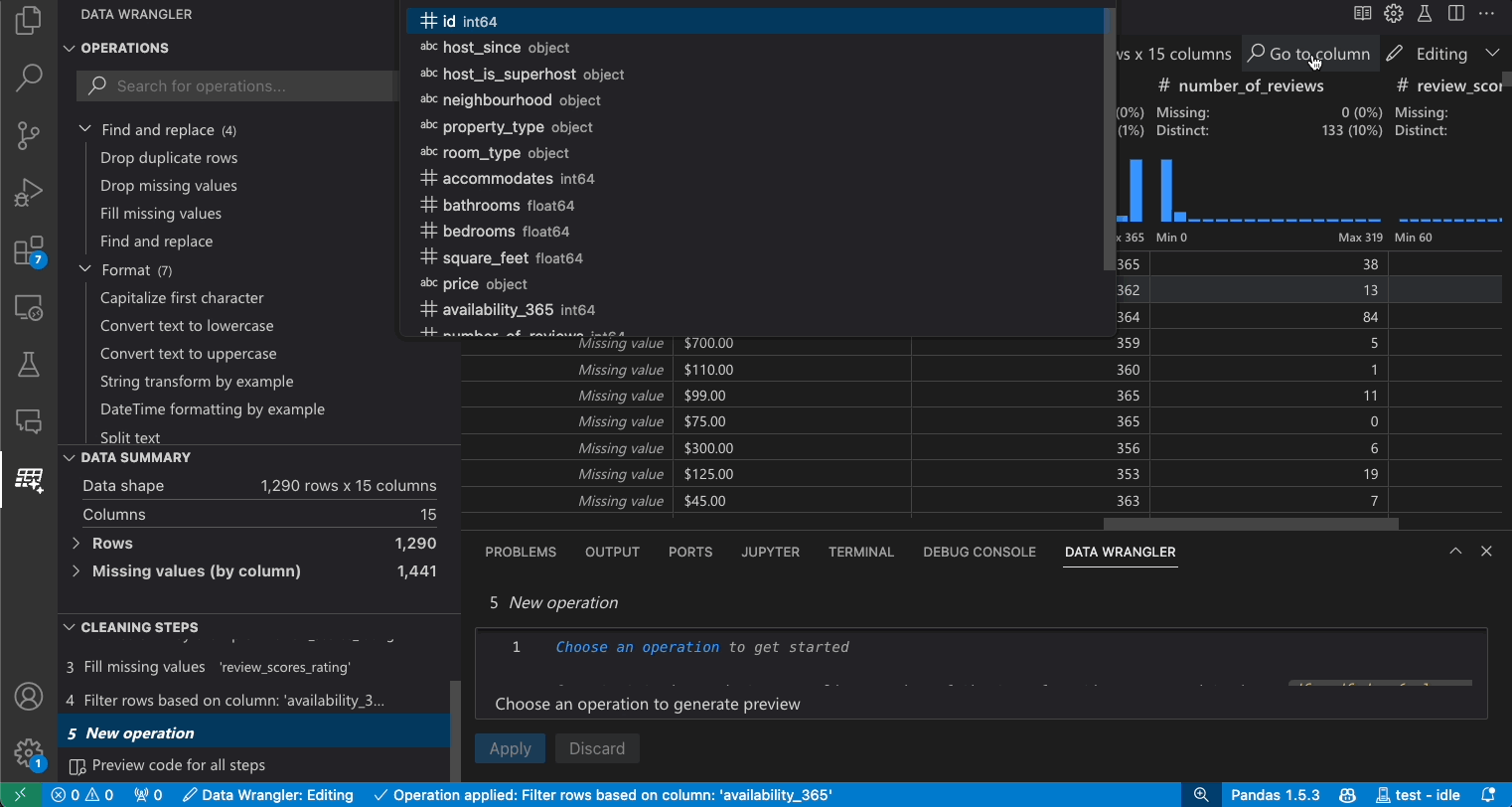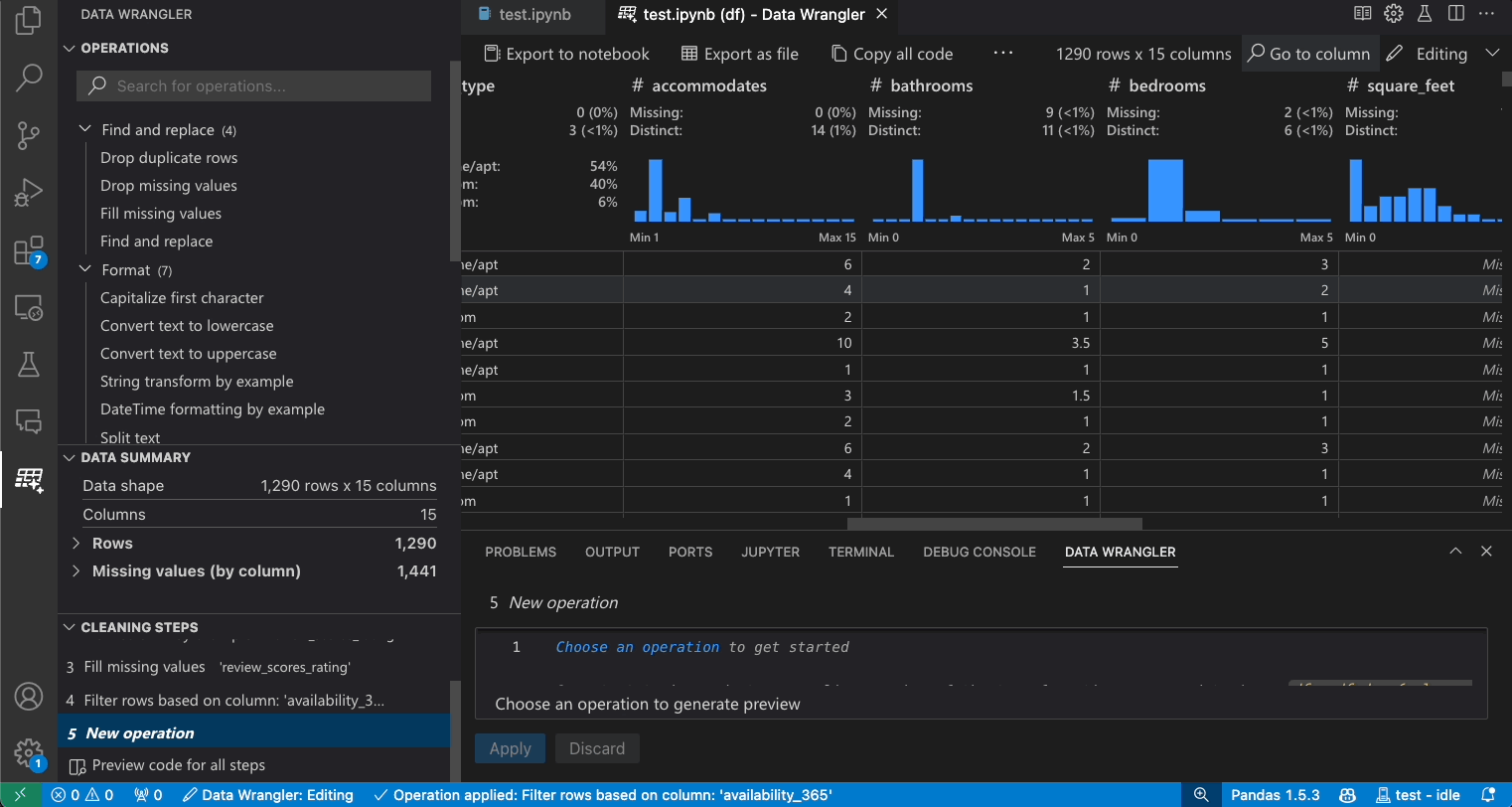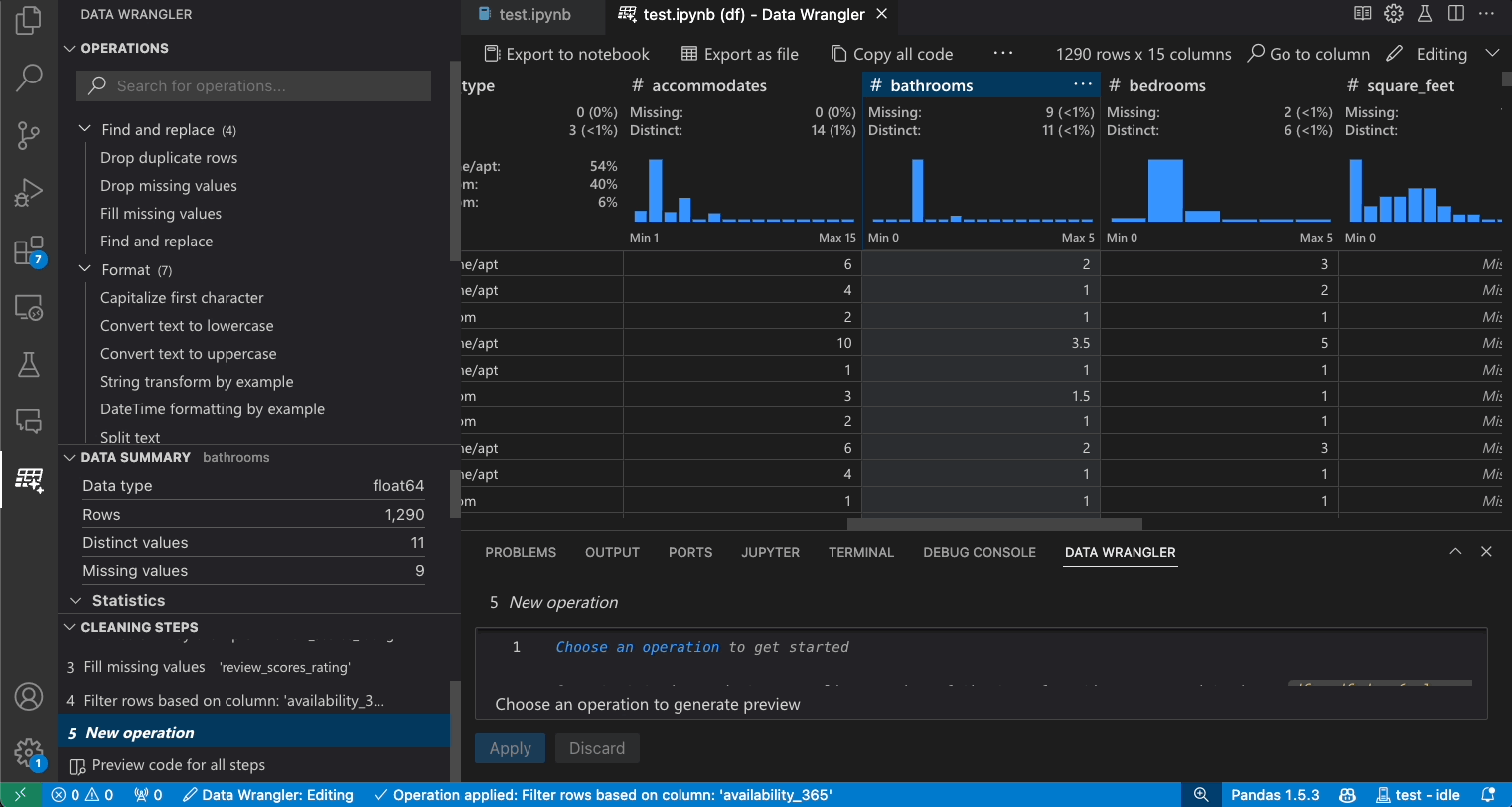
搜索列
要查找数据集中的特定列,请选择转到列,然后在数据整理工具栏中搜索相应的列。
故障排除
通用内核连接问题
对于一般的连接问题,请参阅上面的“连接到Python内核”部分,了解其他连接方法。要调试与本地Python解释器选项相关的问题,潜在的解决方法之一是安装不同版本的Jupyter和Python扩展。例如,如果安装了扩展的稳定版本,您可以安装预发布版本(反之亦然)。
要清除已缓存的内核,您可以运行数据整理器:清除缓存的运行时 从命令面板发出命令 ⇧⌘P (Windows, Linux Ctrl+Shift+P)。
打开数据文件会Unicode解码错误
如果你遇到一个Unicode解码错误当直接从 Data Wrangler 打开数据文件时,这可能是由两个可能的问题引起的:
- 您尝试打开的文件编码与其他编码不同
UTF-8 - 文件已损坏。
要解决此错误,您需要从 Jupyter Notebook 打开 Data Wrangler,而不是直接从数据文件中打开。使用 Jupyter Notebook 通过 Pandas 读取文件,例如使用 read_csv 方法。在 读方法,使用编码和/或编码错误参数来定义使用的编码或如何处理编码错误。如果你不知道这个文件可能适用的编码,可以尝试使用库如chardet来尝试推断出一个适用的编码。
问题和反馈
如果您遇到问题、有功能请求或其他任何反馈,请在我们的 GitHub 仓库上提交一个 Issue:https://github.com/microsoft/vscode-data-wrangler/issues/new/choose
数据和遥测
Microsoft Data Wrangler 扩展程序为 Visual Studio Code 收集使用数据并将其发送给 Microsoft,以帮助改进我们的产品和服务。阅读我们的隐私声明以了解更多信息。此扩展程序尊重遥测.遥测级别在 https://code.visualstudio.com/docs/configure/telemetry 中可以了解更多关于设置的信息。